课前
开篇
- __关注长期变化的软件设计__
- > 设计是为了让软件在长期更容易适应变化。
> Design is there to enable you to keep changing the software easily in the long term. —— Kent Beck
- 算法和软件设计其实是一样的,二者对抗的都是规模问题
- 算法设计 -> 数据规模
- 软件设计 -> 需求规模
- 只有长期的积累,需求才会累积,规模问题才会凸显出来。
- 应对需求的“算法”
- __如何学习__
- 我们困惑的,并不是这些知识本身,而是在于缺乏一个整体结构将它们贯穿起来。
- 多态,这个词在你看来只是一个普通的语法规则,但只有你懂得,它是把变的部分和不变的部分隔离开来,你才能理解开放封闭、接口隔离和依赖倒置这些设计原则的价值所在,理解了这些原则,才能知道某些设计模式只是这些原则在具体场景下的应用
- 软件设计学习的难度,不在于一招一式,而在于 __融会贯通__
- 软件设计” 两个维度
- “了解现有软件的设计”
- “自己设计一个软件”
- 一个快速了解现有软件设计的方法 -> 抓住最核心的三部分
- 模型
- 接口
- 实现
- 软件设计中最重要的部分
- 程序设计语言;
- 编程范式;
- 代码编写的风格,决定着你在设计时可以用到哪些元素:是模块、是对象,还是函数。在不同层次的设计中,选择不同的编程范式已经成为今天开发的主流
- 设计原则;
- SOLID
- 设计模式;
- 看书
- 设计方法
- 领域驱动设计(也就是 DDD,Domain Driven Design)
软件设计
- 多人参与的软件开发, 需要建立起一个统一的结构,以便于所有人都能有一个共同的理解, 即模型
- 模型,是一个软件的骨架,是一个软件之所以是这个软件的核心
- 模型 => 类
- “高内聚、低耦合”,(模块的内聚程度越高越好,模块间的耦合程度越低越好),这其实就是对模型的要求
- 约束的规范
Separation of concerns | 分离关注点
- $$真实的系统 = 功能性的需求 + 非功能性的需求$$
- 非功能性的需求
- 执行质量 (Execution qualities)
- 吞吐、延迟、安全,它们都是可以在运行时通过运维手段被观察到的
- 演化质量 (Evolution qualities)
- 内含于一个软件的结构之中,包括可测试性、可维护性、可扩展性等
- 混淆的关注点
- __业务处理和技术实现__
- 问题
- > 我们经常问怎么处理分布式事务,怎么做分库分表等。其实,你更应该问的是,我的业务需要分布式事务吗?我是不是业务划分没有做清楚,才造成了数据库的压力?
- 解决办法
- 多线程啊!按照我的理解,大部分程序员都不应该编写多线程程序。由专门的程序员把并发处理的部分封装成框架,大家在里面写业务代码就好了
- 在真实项目中,**程序员最常犯的错误就是认为所有问题都是技术问题**,总是试图用技术解决所有问题。**任何试图用技术去解决其他关注点的问题**,只能是陷入焦油坑之中,越挣扎,陷得越深。
- __不同的数据变动方向__
- 不同的数据变动方向还有很多
- 动静分离,就是把变和不变的内容分开;
- 读写分离,就是把读和写分开;
- 前面提到的高频和低频,也可以分解开;
- ……
- 重要
- 不同的关注点混在一起会带来一系列的问题,正如前面提到的各种问题
- 当分解得足够细小,你就会发现不同模块的共性,才有机会把同样的信息聚合在一起
可测试性
- 复杂的系统不仅仅在测试上有难度,在集成、部署等各个环节,都有其复杂性,完成一次部署往往也需要很长时间。这也就意味着,即便是一个简单的验证工作,部署的时间成本也非常昂贵。这还不包括在出问题时,我们在一个复杂系统中定位问题的成本
- 集成测试
- __从最外围的系统角度去验证系统的正确性,这将会是一个非常困难的过程__
- 这些问题原本可以在更前面的阶段解决,比如,单元测试
- 和盖楼是一个道理,不保证钢筋、水泥、砖土质量合格,却想要盖出合格的大楼来,很荒唐吧!
- >[!tip]
> __要在设计时想一下,这个函数/模块/系统要怎么测__
- 尽可能地给每个模块更多的测试
- 使构成系统的每个模块尽可能稳定,把集成测试环境更多地留作公共的验收资源。
- 尽可能搭建本地的集成测试环境
- 周边的系统可以采用模拟服务的方案。在软件开发过程中考虑测试,实际上是思考软件的质量问题,而把质量的思考前移到开发,甚至是设计阶段,是软件开发从传统进入到现代的重要一步
class ProductService { // 访问数据库的对象 private ProduceRepository repository = new ProductRepository (); public Product find ( final long id ) { return this .repository. find (id); } } // 生产环境 + 创建数据库访问的对象 + 数据库连接... => 测试的复杂度就会非常大 class ProductService { // 访问数据库的对象 private ProduceRepository repository; //NOTE: 我们只需要将数据访问的接口模拟出来, // 用来模拟接口的 Mock 框架在各种程序语言里几乎都可以找到 public ProductService ( final ProduceRepository repository ) { this .repository = repository; } public Product find ( final long id ) { return this .repository. find (id); } } //我们唯一要保证的,就是模拟出来的对象要与接口定义的行为保持一致,这可比准备数据库,难度系数要低多了 了解软件设计
三步走
- 模型/抽象 -> 接口 -> 实现
- 它属于实现,是可能被替换的
- 模型 / 抽象
- 你在编写分布式计算代码时,需要考虑怎样在不同的节点上调度计算;而使用MapReduce时,只要考虑如何把计算分开(Map)最后再汇总(Reduce);而到了Spark,注意力就集中在要做怎样的计算上。它们在解决同样的问题,只是抽象层次逐步提高了,越来越接近要解决的问题,越来越少地考虑计算在不同的机器上是如何执行的,由此,降低了理解的门槛
- 接口 / API
- 每个人会设计出不同的API,而不同的API有着不同的表达能力
- Google的Guava对JDK的一些API重新做了封装,其目的就是简化开发,而很多优秀的做法后来又被JDK学了回去
- 一个工具软件一般会提供命令行接口,比如,每个程序员必备的基本技能——Unix命令行工具就是典型的命令行接口
- 一个业务系统的接口,就是对外暴露的各种接口,比如,它提供的各种RESTAPI,也可能是提供了RPC给其它系统的调用
- 如果你想深入源码,去了解一个软件,接口是一个很好的指向标。你可以从一个接口进入到软件中,看它是怎样完成各种基本功能的
- 实现
- 在实际的工作中,我发现许多人以为的设计其实是这里所讲的实现
- 稳定度低
- 实现必须建立在模型和接口的基础之上。因为在一个系统的设计中,模型是最核心的部分。如果模型变了,这个软件便不再是这个软件了,而接口通常反映的就是模型。
- 很多人都知道Redis这个键值对存储性能非常好,他们学习Redis时,对其单线程模型印象深刻,因为它简单高效。但随着人们使用Redis的增多,对Redis有了进一步的需求。所以,从6.0开始,它开始支持多线程版本,以便于更好地满足人们的需求。但即便Redis改成了多线程,它还是那个Redis, __它的模型和接口还是一如既往,只是实现变了而已__
- ![[image_1646124149417_0.png]]
- 把 __模型__ 和 __实现__ 混淆了
- 图中的订单、支付和物流,说的都是模型层面的东西,但Kafka的出现,就把实现层面的东西拉了进来。Kafka只是实现这个功能时的一个技术选型,这也就意味着,如果随着业务的发展,它不能很好地扮演它的角色,你就可以替换掉它,而整个设计是不用变的
- 实现这段代码的时候,必须把 Kafka 相关的代码进行封装,不能在系统各处随意地调用,因为它属于实现,是可能被替换的
- 以操作系统进程管理为例
- 进程管理的核心模型就包括进程模型和调度算法;
- 它的接口就包括,进程的创建、销毁以及调度算法的触发等;
- 不同调度算法就是一个个具体的实现
- 操作系统课程难以学习,很大程度上就在于,很多人没有搞清楚其中各个概念之间的关系
- Java 面试题常问到的 HashMap
- 它的模型就是我们在数据结构中学习的HashMap;
- 它定义了一些接口,比如,get、put等;
- 它的实现原来是用标准的HashMap实现,后来则借鉴了红黑树
05 | Spring DI容器:如何分析一个软件的模型?
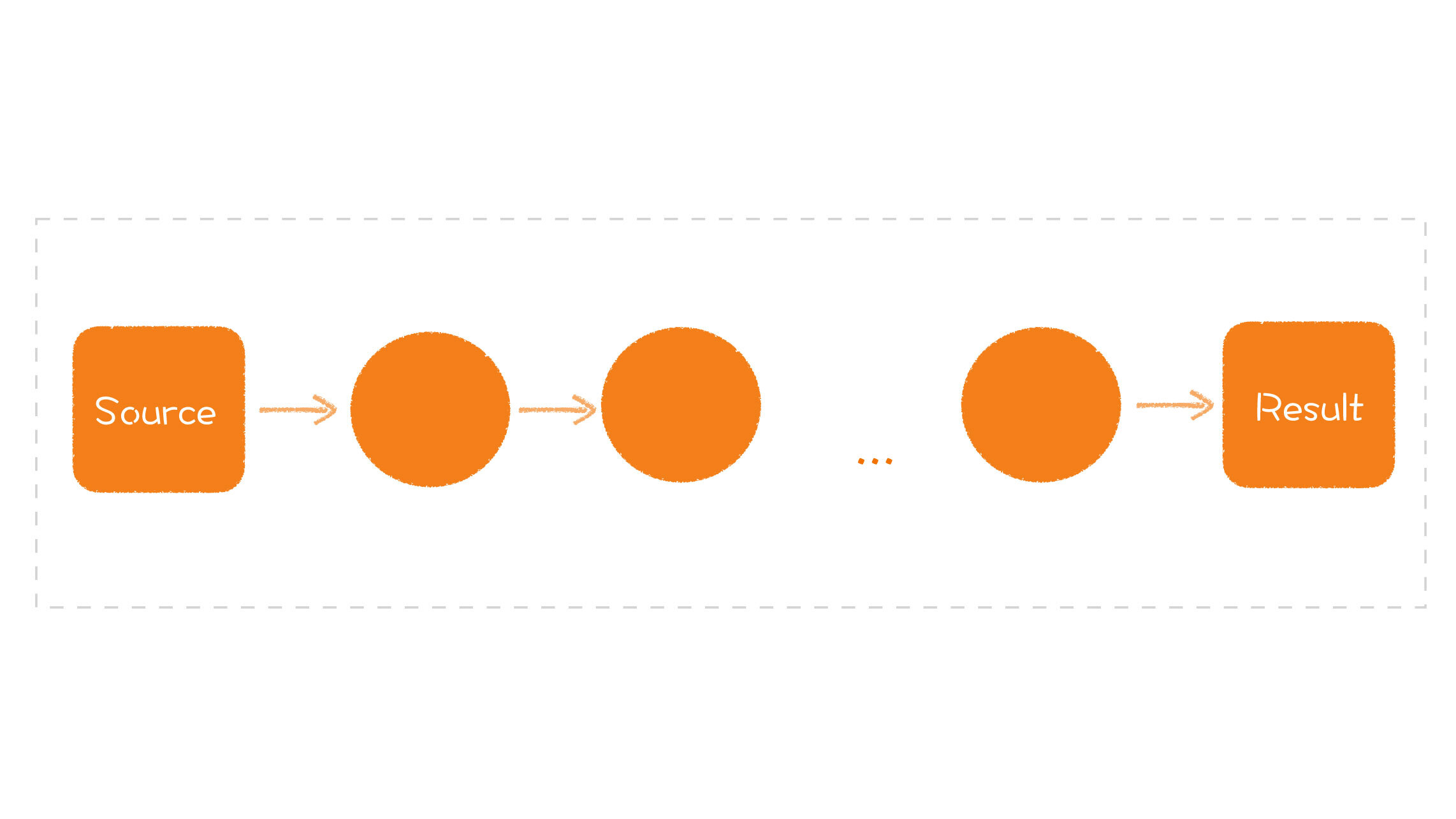
在上一讲中,我们讨论了如何了解一个软件的设计,主要是从三个部分入手:模型、接口和实现。那么,在接下来的三讲中,我将结合几个典型的开源项目,告诉你如何具体地理解一个软件的模型、接口和实现。
今天这一讲,我们就先来谈谈了解设计的第一步:模型。如果拿到一个项目,我们怎么去理解它的模型呢?
我们肯定要先知道项目提供了哪些模型,模型又提供了怎样的能力。这是所有人都知道的事情,我并不准备深入地去探讨。但如果只知道这些,你只是在了解别人设计的结果,这种程度并不足以支撑你后期对模型的维护。
在一个项目中,常常会出现新人随意向模型中添加内容,修改实现,让模型变得难以维护的情况。造成这一现象的原因就在于他们对于模型的理解不到位。
我们都知道,任何模型都是为了解决问题而生的,所以,理解一个模型,需要了解在没有这个模型之前,问题是如何被解决的,这样,你才能知道新的模型究竟提供了怎样的提升 。也就是说,理解一个模型的关键在于,要了解这个模型设计的来龙去脉,知道它是如何解决相应的问题。
今天我们以 Spring 的 DI 容器为例,来看看怎样理解软件的模型。
耦合的依赖
- Spring 在 Java 世界里绝对是大名鼎鼎,如果你今天在做 Java 开发而不用 Spring,那么你大概率会被认为是个另类。
- 今天很多程序员都把 Spring 当成一个成熟的框架,很少去仔细分析 Spring 的设计。但作为一个从 0.8 版本就开始接触 Spring 的程序员,我刚好有幸经历了 Spring 从渺小到壮大的过程,得以体会到 Spring 给行业带来的巨大思维转变。
- 如果说 Spring 这棵参天大树有一个稳健的根基,那其根基就应该是 Spring 的 DI 容器。==DI 是 Dependency Injection 的缩写,也就是“依赖注入”。Spring 的各个项目都是这个根基上长出的枝芽==。
- 那么,DI 容器要解决的问题是什么呢?==它解决的是组件创建和组装的问题==,但是为什么这是一个需要解决的问题呢?这就需要我们了解一下组件的创建和组装。
- 在前面的课程中,我讲过,软件设计需要有一个分解的过程,所以,它必然还要面对一个组装的过程,也就是把分解出来的各个组件组装到一起,完成所需要的功能。
- 为了叙述方便,我采用 Java 语言来进行后续的描述。我们从程序员最熟悉的一个查询场景开始。假设我们有一个文章服务(ArticleService)提供根据标题查询文章的功能。当然,数据是需要持久化的,所以,这里还有一个 ArticleRepository,用来与持久化数据打交道。
- 熟悉 DDD 的同学可能发现了,==这个仓库(Repository)的概念来自于 DDD==。如果你不熟悉也没关系,它就是与持久化数据打交道的一层,和一些人习惯的 Mapper 或者 DAO(Data Access Object)类似,你可以简单地把它理解成访问数据库的代码。
class ArticleService {
Article findByTitle(final String title) {
...
}
}
interface ArticleRepository {
Article findByTitle(final String title);
}
- 在 ArticleService 处理业务的过程中,需要用到 ArticleRepository 辅助它完成功能,也就是说,ArticleService 要依赖于 ArticleRepository。这时你该怎么做呢?一个直接的做法就是在 ArticleService 中增加一个字段表示 ArticleRepository。
class ArticleService {
private ArticleRepository repository;
public Article findByTitle(final String title) {
return this.repository.findByTitle(title);
}
}
- 目前看起来一切都还好,但是接下来,问题就来了,这个字段怎么初始化呢?程序员一般最直接的反应就是直接创建这个对象。这里选用了一个数据库版本的实现(DBArticleRepository)。
class ArticleService {
private ArticleRepository repository = new DBArticleRepository();
public Article findByTitle(final String title) {
return this.repository.findByTitle(title);
}
}
- 看上去很好,但实际上 DBArticleRepository 并不能这样初始化。正如这个实现类的名字所表示的那样,我们这里要用到数据库。但在真实的项目中,==由于资源所限,我们一般不会在应用中任意打开数据库连接,而是会选择共享数据库连接。所以,DBArticleRepository 需要一个数据库连接(Connection)的参数==。在这里,你决定在构造函数里把这个参数传进来。
class ArticlService {
private ArticleRepository repository;
public ArticlService(final Connection connection) {
this.repository = new DBArticleRepository(connection);
}
public Article findByTitle(final String title) {
return this.repository.findByTitle(title);
}
}
- 好,代码写完了,它看上去一切正常。如果你的开发习惯仅仅到此为止,可能你会觉得这还不错。但我们并不打算做一个只写代码的程序员,所以,我们要进入下一个阶段:测试。
- 一旦开始准备测试,你就会发现,要让 ArticleService 跑起来,那就得让 ArticleRepository 也跑起来;要让 ArticleRepository 跑起来,那就得准备数据库连接。
- 是不是觉得太麻烦,想放弃测试。但有职业素养的你,决定坚持一下,去准备数据库连接信息。
- 然后,真正开始写测试时,你才发现,要测试,你还要在数据库里准备各种数据。比如,要测查询,你就得插入一些数据,看查出来的结果和插入的数据是否一致;要测更新,你就得先插入数据,测试跑完,再看数据更新是否正确。
- 不过,你还是没有放弃,咬着牙准备了一堆数据之后,你突然困惑了:我在干什么?我不是要测试服务吗?==做数据准备不是测试仓库的时候应该做的事吗==?
- 那么,问题出在哪儿呢?==其实就在你创建对象的那一刻,问题就出现了==。
分离的依赖
- 为什么说从创建对象开始就出问题了呢?
- ==因为当我们创建一个对象时,就必须要有一个具体的实现类,对应到我们这里,就是那个 DBArticleRepository。虽然我们的 ArticleService 写得很干净,其他部分根本不依赖于 DBArticleRepository,只在构造函数里依赖了,但依赖就是依赖==。
- 与此同时,由于要构造 DBArticleRepository 的缘故,我们这里还引入了 ==Connection 这个类,这个类只与 DBArticleRepository 的构造有关系,与我们这个 ArticleService 的业务逻辑一点关系都没有==。
- 所以,你看到了,只是因为引入了一个具体的实现,我们就需要把它周边配套的东西全部引入进来,而这一切与这个类本身的业务逻辑没有任何关系。
- 这就好像,你原本打算买一套家具,现在却让你必须了解树是怎么种的、怎么伐的、怎么加工的,以及家具是怎么设计、怎么组装的,而你想要的只是一套能够使用的家具而已。
- 这还只是最简单的场景,在真实的项目中,构建一个对象可能还会牵扯到更多的内容:
- 根据不同的参数,创建不同的实现类对象,你可能需要用到工厂模式。
- 为了了解方法的执行时间,需要给被依赖的对象加上监控。
- 依赖的对象来自于某个框架,你自己都不知道具体的实现类是什么。
- 所以,即便是最简单的对象创建和组装,也不像看起来那么简单。
- 既然直接构造存在这么多的问题,那么最简单的办法就是把创建的过程拿出去,只留下与字段关联的过程:
class ArticleService {
private ArticleRepository repository;
public ArticleService(final ArticleRepository repository) {
this.repository = repository;
}
public Article findByTitle(final String title) {
return this.repository.findByTitle(title);
}
}
- 这时候,ArticleService 就只依赖 ArticleRepository。而测试 ArticleService 也很简单,只要用一个对象将 ArticleRepository 的行为模拟出来就可以了。==通常这种模拟对象行为的工作用一个现成的程序库就可以完成,这就是那些 Mock 框架能够帮助你完成的工作==。
- 或许你想问,在之前的代码里,如果我用 Mock 框架模拟 Connection 类是不是也可以呢?理论上,的确可以。但是想要让 ArticleService 的测试通过,就必须打开 DBArticleRepository 的实现,只有配合着其中的实现,才可能让 ArticleService 跑起来。显然,你跑远了。
- 现在,对象的创建已经分离了出去,但还是要要有一个地方完成这个工作,最简单的解决方案自然是,把所有的对象创建和组装在一个地方完成:
...
ArticleRepository repository = new DBArticleRepository(connection);
AriticleService service = new ArticleService(repository);
...
- 相比于业务逻辑,组装过程并没有什么复杂的部分。一般而言,纯粹是一个又一个对象的创建以及传参的过程,这部分的代码看上去会非常的无聊。
- 虽然很无聊,但这一部分代码很重要,最好的解决方案就是有一个框架把它解决掉。==在 Java 世界里,这种组装一堆对象的东西一般被称为“容器”,我们也用这个名字==。
Container container = new Container();
container.bind(Connection.class).to(connection);
container.bind(ArticleReposistory.class).to(DBArticleRepository.class);
container.bind(ArticleService.class).to(ArticleService.class)
ArticleService service = container.getInstance(ArticleService.class);
- 至此,==一个容器就此诞生。因为它解决的是依赖的问题,把被依赖的对象像药水一样,注入到了目标对象中,所以,它得名“依赖注入”(Dependency Injection,简称 DI)。这个容器也就被称为 DI 容器了==。
- 至此,我简单地给你介绍了 DI 容器的来龙去脉。虽然上面这段和 Spring DI 容器长得并不一样,但其原理是一致的,只是接口的差异而已。
- 事实上,==这种创建和组装对象的方式在当年引发了很大的讨论,直到最后 Martin Fowler 写了一篇《反转控制容器和依赖注入模式》的文章,才算把大家的讨论做了一个总结,行业里总算是有了一个共识==。
- 那段时间,DI 容器也得到了蓬勃的发展,很多开源项目都打造了自己的 DI 容器,Spring 是其中最有名的一个。只不过,Spring 并没有就此止步,而是在这样一个小内核上面发展出了更多的东西,这才有了我们今天看到的庞大的 Spring 王国。
- 讲到这里,你会想,那这和我们要讨论的“模型”有什么关系呢?
- 正如我前面所说,很多人习惯性把对象的创建和组装写到了一个类里面,这样造成的结果就是,代码出现了大量的耦合。时至今日,很多项目依然在犯同样的错误。很多项目测试难做,原因就在于此。这也从另外一个侧面佐证了可测试性的作用,我们曾在第 3 讲中说过:可测试性是衡量设计优劣的一个重要标准。
- 由此可见,在没有 DI 容器之前,那是怎样的一个蛮荒时代啊!
- 有了 DI 容器之后呢?
- ==你的代码就只剩下关联的代码,对象的创建和组装都由 DI 容器完成了。甚至在不经意间,你有了一个还算不错的设计:至少你做到了面向接口编程,它的实现是可以替换的,它还是可测试的。与之前相比,这是一种截然不同的思考方式,而这恰恰就是 DI 容器这个模型带给我们的==。
- 而且,一旦有了容器的概念,它还可以不断增强。比如,==我们想给所有与数据库相关的代码加上时间监控,只要在容器构造对象时添加处理即可。你可能已经发现了,这就是 AOP(Aspect Oriented Programming,面向切面编程)的处理手法。而这些改动,你的业务代码并无感知==。
- Spring 的流行,对于提升 Java 世界整体编程的质量是大有助益的。因为它引导的设计方向是一个好的方向,==一个普通的 Java 程序员写出来的程序只要符合 Spring 引导的方向,那么它的基本质量就是有保障的,远超那个随意写程序的年代==。
- 不过,如果你不能认识到 DI 容器引导的方向,我们还是无法充分利用它的优势,更糟糕的是,我们也不能太低估一些程序员的破坏力。我还是见过很多程序员即便在用了 Spring 之后,依然是自己构造对象,静态方法满天飞,把原本一个还可以的设计,打得七零八落。
- 你看,通过上面的分析,我们知道了,只有理解了模型设计的来龙去脉,清楚认识到它在解决的问题,才能更好地运用这个模型去解决后面遇到的问题。如果你是这个项目的维护者,你才能更好地扩展这个模型,以便适应未来的需求。
- 
思考题
- 最后,我想请你思考一个问题,DI 容器看上去如此地合情合理,为什么在其他编程语言的开发中,它并没有流行起来呢?欢迎在留言区写下你的思考。
- 感谢阅读,如果你觉得这一讲的内容对你有帮助的话,也欢迎把它分享给你的朋友。
06 | Ruby on Rails:如何分析一个软件的接口?
在上一讲中,我以 Spring 的 DI 容器为例,给你讲解了如何理解一个项目的模型。在模型之后,下一步就该是接口了。
在任何一个项目中,接口的数量都不是一个小数目。仅仅一个普通的程序库,里面的接口少则几十个,多则成百上千。难道我们理解接口,就是要一个一个地读这些接口吗?
显然,你不太可能把所有的接口细节都记住。我写 Java 程序差不多 20 年了,但很多 JDK 里的类我都不了解。甚至有时候,还没有等我去了解这个类,它就过时了 。
那么,如何才能从纷繁复杂的接口中,披荆斩棘而出呢?我给你个方法:找主线,看风格 。
找主线的意思是,你需要找到一条功能主线,建立起对这个项目结构性的认知,而不是一上来就把精力放在每一个接口的细节上。你对细节部分的了解会随着你对项目的深入而逐渐增加。而有了主线后,你就有了着力点,就可以不断深入了 。
但是,我们要学习的不只是这些接口的用法,要想从项目的接口设计上学到更多,这就需要你关注它所引导的风格,换句话说,就是它希望你怎样使用它,或是怎样在上面继续开发。
从一个项目的接口风格中,我们不难看出设计者的品位。我们常把编程视为一种艺术,而在接口的设计上就能窥见一二。这些内容是我们在学习软件设计时,应该慢慢品味的。
为什么要看风格,还有一个很重要的原因,就是你要维护项目的一致性,必须有一个统一的风格。有不少项目,里面会共存多种不同风格的接口,就是每个人都在设计自己习惯的接口,那势必会造成混乱。
这一讲,我们就来一起来学习怎样看接口,我选择的项目是 Ruby on Rails,因为它的接口设计风格是带给我最多震撼的,无论是编程接口的优雅,还是开发过程接口的顺畅。不过,正如我在第 4 讲所说,看设计要先看模型。所以,我们还是先快速地了解一下 Ruby on Rails 的模型。
Ruby on Rails 模型
- 如果你是一个比较年轻的程序员,Ruby on Rails 这个名字可能会让你有一些陌生。但是在十多年前,它初出茅庐之际,可是给行业带来了极大的冲击。只是后来时运不济,编程模型发生了大的改变,使它失去了行业领导者的地位。这个故事还是要从你最熟悉的 Web 开发说起。
- 自从互联网兴起,人们对于 Web 开发的探索就从未停止过。
- 最早期的 Web 开发只是静态页面的开发,那时候,你只要熟悉 HTML,就可以说自己懂 Web 开发了。后来,人们不再满足于静态页面,开始尝试编写有动态效果的页面。
- 一方面,浏览器开始支持 JavaScript,让页面本身有了动态效果;另一方面,有人开始制作后台服务,在页面之间切换的时候,也可以有动态的效果。那个时候出现了像 CGI(Common Gateway Interface)这样的编程规范。
- 当 Java 世界里出现了 Servlet、JSP 这些规范,Web 开发也逐渐由小打小闹变成了企业开发的主力,越来越多的公司开始正视 Web 开发。因为这些规范很沉重,一些号称要简化 Web 开发的框架开始出现,比如:Struts、Webwork 以及 Spring MVC 等等。
- 这些框架的出现,让 Web 开发摆脱了 Servlet 的初级阶段,使 MVC 模式成为了 Web 开发的主流。但即便如此,那个时候的 Java Web 开发依然是沉重的,比如写一个 Web 应用,光是配置文件就足以把人逼疯。
- Ruby on Rails 正是在这样的背景下横空出世的。为了叙述方便,后面我就把 Ruby on Rails 简称 Rails 了。
- 从模型上讲,Rails 是标准的基于 MVC 模型进行开发的 Web 框架。在这一点上,它没有什么特殊的,它给行业带来巨大冲击的是它的接口设计。
- ==Rails 一个重要的设计理念就是约定优于配置,无需配置,按照缺省的风格就可以完成基本的功能,这样的理念贯穿在 Rails 各个接口的设计中==。
- 接下来,我们就来看 Rails 的接口。
- 前面我提到过理解接口应该先找主线,找到项目主线的一个方法就是从起步走文档开始,因为它会把项目最基本的用法展现给你,你可以轻松地找到主线。
- Rails 的起步走文档做得就非常好,主线可以说是一目了然。它用了一个 Web 项目帮你介绍了 Rails 开发的基本过程,通过这个过程,你就对 Rails 有了初步的印象。
- 有了主线之后,我们就要开始从中了解接口的风格。Rails 给我们提供的三种接口,分别是:
- Web 应用对外暴露的接口:REST API;
- 程序员写程序时用到的接口:API;
- 程序员在开发过程中用到的接口:命令行。
- 接下来,我们就一个个地深入其中,了解它们的风格,以及它们给行业带来的不同思考。
REST 接口
- 先说应用对外暴露的接口:REST API。REST 如今已经成为很多人耳熟能详的名词,==它把 Web 的各种信息当作资源。既然是资源,它就可以对这些 Web 信息做各种操作,这些操作对应着 HTTP 的各种动词(GET、POST、PUT、DELETE 等)==。
- REST 当年的问世是 Roy Fielding 博士为了纠正大家对 HTTP 的误用。 REST 刚出来的时候,开发者普遍觉得这是一个好的想法,但怎么落地呢?没有几个人想得清楚。
- Rails 恰逢其时地出现了。Rails 对 REST 的使用方式做了一个约定。只要你遵循 Rails 的惯用写法,写出来的结果基本上就是符合 REST 结构的,也就是说,Rails 把 REST 这个模型用一种更实用的方式落地了。
Rails.application.routes.draw do
...
resources :articles
...
end
- 在用 Rails 写程序的时候,你只要添加一个 resource 进去,它就会替你规划好这个资源应该如何去写、怎么设计 URL、用哪些 HTTP 动词,以及它们对应到哪些方法。
$ bin/rails routes
Prefix Verb URI Pattern Controller#Action
articles GET /articles(.:format) articles#index
POST /articles(.:format) articles#create
new_article GET /articles/new(.:format) articles#new
edit_article GET /articles/:id/edit(.:format) articles#edit
article GET /articles/:id(.:format) articles#show
PATCH /articles/:id(.:format) articles#update
PUT /articles/:id(.:format) articles#update
DELETE /articles/:id(.:format) articles#destroy
root GET / welcome#index
- 看了 Rails 给你的这个映射关系后,你就知道自己该怎么写代码了。==这就是一种约定,不需要你费心思考,因为这是人家总结出来的行业中的最佳实践。只要按照这个规范写,你写的就是一个符合 REST 规范的代码,这就是 Rails 引导的外部接口风格==。
API 接口
- 我们再来看 API 接口。当年我接触 Rails 时,最让我感到震惊的是它的数据库查询方式,与传统开发的风格截然不同,就这么简单的一句:
Article.find_by_title("foo")
- 要知道,那个时候用 Java 写程序,即便是想做一个最简单的查询,写的代码也是相当多的。我们不仅要创建一个对象,还要写对应的 SQL 语句,还要把查询出来的结果,按照一定的规则组装起来。
- 而 Rails 用一句轻描淡写 find\_by 就解决了所有的问题,而且,这个 find\_by\_title 方法还不是我实现的,Rails 会替你自动实现。当我们需要有更多的查询条件时,只要一个一个附加上去就可以了。
Article.find_by_title_and_author("foo", "bar")
- 同样的事,如果放到 Java 里去做,还需要把前面说的事再做一遍,差别只是查询语句不一样。
- 虽然我说的是当年的场景,但时至今日,在这些简单问题上,很多使用 Java 的团队所付出的工作量并不比当年少。
- 从功能的角度说,这样的查询在功能上是完全一样的,但==显然 Rails 程序员和 Java 程序员的工作量是天差地别的。这其中的差异就是不同的编程接口所造成的==。
- 所以你看,一个好的接口设计会节省很多工作量,会减少犯错的几率。因为它会在背后帮你实现那些细节。
- 而设计不好的接口,则会把其中的细节暴露出来,让使用者参与其中。写程序库和写应用虽然都是写代码,但二者的要求确实相差极大。把细节暴露给所有人,显然是一个增加犯错几率的事情。
- Rails 的 API 接口给行业带来的另一个影响是,它让人们开始关注 API 的表达性。比如,每篇文章可以有多个评论,用 Rails 的方式写出来是这样的:
class Article < ApplicationRecord
has_many :comments
...
end
- 而如果用传统 Java 风格,你写出来的代码,可能是这个样子的:
class Article {
private List<Comment> comments;
...
- 很明显,“有多个”这种表示关系的语义用 has\_many 表示更为直白,如果用 List ,你是无法辨别它是一个属性,还是一个关系的。
- Rails 里面类似的代码有很多,包括我们前面提到的 find\_by。所以,如果你去读 Rails 写成的应用,会觉得代码的可读性要好得多。
- 由于 Rails 的蓬勃发展,人们也开始注意到好接口的重要性。Java 后期的一些开源项目也开始向 Rails 学习。比如,使用 Spring Data JPA 的项目后,我们也可以写出类似 Rails 的代码。声明一对多的关系,可以这样写:
class Article {
private List<Comment> comments;
...
- 而查询要定义一个接口,代码可以这样写:
interface ArticleRepository extends JpaRepository<Article, Long> {
Article findByTitle(String title);
Article findByTitleAndAuthor(String title, String author);
}
- 当你需要使用的时候,只要在服务里调用对应的接口即可。
class ArticleService {
private ArticleRepository repository;
...
public Article findByTitle(final String title) {
return repository.findBytitle(title);
}
}
- 显然,==Java 无法像 Rails 那样不声明方法就去调用,因为这是由 Ruby 的动态语言特性支持的,而 Java 这种编译型语言是做不到的。不过比起从前自己写 SQL、做对象映射,已经减少了很多的工作量==。
- ==顺便说一下,Spring Data JPA 之所以能够只声明接口,一个重要的原因就是它利用了 Spring 提供的基础设施,也就是上一讲提到的依赖注入。它帮你动态生成了一个类,不用你自己手工编写==。
- 简单,表达性好,这就是 Rails API 的风格。
命令行接口
- 作为程序员,我们都知道自动化的重要性,但 Rails 在“把命令行的接口和整个工程配套得浑然一体”这个方面做到了极致。Rails 的自动化不仅会帮你做一些事情,更重要的是,它还把当前软件工程方面的最佳实践融合进去,这就是 Rails 的命令行风格。
- 如果要创建一个新项目,你会怎么做呢?使用 Rails,这就是一个命令:
$ rails new article-app
- 这个命令执行的结果生成的不仅仅是源码,还有一些鼓励你去做的最佳实践,比如:
- 它选择了 Rake 作为自动化管理的工具,生成了对应的 Rakefile;
- 它选择了 RubyGem 作为包管理的工具,生成了对应的 Gemfile;
- 为防止在不同的人在机器上执行命令的时间不同,导致对应的软件包有变动,生成了对应的 Gemfile.lock,锁定了软件包的版本;
- 把对数据库的改动变成了代码;
- ...
- 而这仅仅是一个刚刚生成的工程,我们一行代码都没有写,它却已经可以运行了。
$ bin/rails server
- 这就启动了一个服务器,访问 http://localhost:3000/ 这个 URL,你就可以访问到一个页面。
- 如果你打算开始编写代码,你也可以让它帮你生成代码骨架。执行下面的命令,它会帮你生成一个 controller 类,生成对应的页面,甚至包括了对应的测试,这同样是一个鼓励测试的最佳实践。
bin/rails generate controller Welcome index
- 在 Rails 蓬勃发展的那个时代,人们努力探索着 Web 开发中各种优秀的做法,而在这个方面走在最前沿的就是 Rails。所以,那个时候,我们经常会关注 Rails 的版本更新,看看又有哪些好的做法被融入其中。
- Rails 中那些优秀的实践逐步地被各种语言的框架学习着。语言编写者们在设计各种语言框架时,也都逐步借鉴了 Rails 中的那些优秀实践。比如,==今天做 Java 开发,我们也会用到数据库迁移的工具,比如 Flyway==。
- 当然,另一个方面,即便到了今天,大部分项目的自动化整合程度也远远达不到 Rails 的高度,可能各方面的工具都有,但是如此浑然一体的开发体验,依然是 Rails 做得最好。
- 最后,你可能会问,Rails 这么优秀,为什么今天却落伍了呢?
- 在 Web 开发领域,==Rails 可谓成也 MVC,败也 MVC。MVC 是那个时代 Web 开发的主流,页面主要在服务端进行渲染。然而,后来风云突变,拜 JavaScript 虚拟机 V8 所赐,JavaScript 能力越来越强,Node.js 兴起,人们重新认识了 JavaScirpt。它从边缘站到了舞台中心,各种组件层出不穷,前端页面的表现力大幅度增强==。
- Web 开发的模式由原来的 MVC,逐渐变成了前端提供页面,后端提供接口的方式。Java 的一些框架和服务也逐步发展了起来,Spring 系列也越来越强大,重新夺回了 Web 后端开发的关注。
- 
07 | Kafka:如何分析一个软件的实现?
上一讲,我们学习了如何看接口,今天我们进入第三个部分——看实现。在一个系统中,模型和接口是相对稳定的部分。但是,同样的模型和接口,如果采用不同的实现,稳定性、可扩展性和性能等诸多方面相差极大。而且,只有了解实现,你才有改动代码的基础。
但是,不得不说,“看实现”是一个很大的挑战,因为有无数的细节在那里等着你。所以,在很多团队里,一个新人甚至会用长达几个月的时间去熟悉代码中的这些细节。
面对这种情况,我们该怎么办呢?
首先,你要记住一件事,你不太可能记住真实项目的所有细节,甚至到你离开项目的那一天,你依然会有很多细节不知道,可这并不妨碍你的工作。但是,如果你心中没有一份关于项目实现的地图,你就一定会迷失 。
像我前面所说的新人,他们用几个月的时间熟悉代码,就是在通过代码一点点展开地图,但是,这不仅极其浪费时间,也很难形成一个整体认知。所以我建议,你应该直接把地图展开。怎么展开呢?你需要找到两个关键点:软件的结构和关键的技术 。
可能你还不太理解我的意思,下面我就以开源软件 Kafka 为例,给你讲一下如何把地图展开,去看一个软件的实现。按照我们之前讲过的思路,了解一个软件设计的步骤是“先模型,再接口,最后看实现”。所以,我们要先了解 Kafka 的模型和接口。
消息队列的模型与接口
- Kafka 是这么自我介绍的:Kafka 是一个分布式流平台。这是它现在的发展方向,但在更多人的心目中,Kafka 的角色是一个消息队列。可以说,消息队列是 Kafka 这个软件的核心模型,而流平台显然是这个核心模型存在之后的扩展。所以,我们要先把焦点放在 Kafka 的核心模型——消息队列上。
- 简单地说, 消息队列(Messaging Queue)是一种进程间通信的方式,发消息的一方(也就是生产者)将消息发给消息队列,收消息的一方(也就是消费者)将队列中的消息取出并进行处理。
- 站在看模型的角度上,消息队列是很简单的,无非是生产者发消息,消费者消费消息。而且消息队列通常还会有一个 topic 的概念,用以区分发给不同目标的消息。
- 消息队列的基本接口也很简单。以 Kafka 为例,生产者是这样发消息的:
producer.send(new KafkaRecord<>("topic", new Message()));
- 而消费者收消息是这样的:
ConsumerRecords<String, Message> records = consumer.poll(1000);
- 有了对模型和接口的基本了解,我们会发现,消息队列本身并不难。
- 但我们都知道,消息队列的实现有很多,Kafka 只是其中一种,还有诸如 ActiveMQ、RabbitMQ 等的实现。为什么会有这么多不同的消息队列实现呢?==因为每个消息队列的实现都会有所侧重,不同的消息队列有其适用的场景==。
- 消息队列还有一个最常见的特性是,它会提供一定的消息存储能力。这样的话,当生产者发消息的速度快于消费者处理消息的速度时,消息队列可以起到一定的缓冲作用。所以,==有一些系统会利用消息队列的这个特性做“削峰填谷”,也就是在消息量特别大时,先把消息收下来,慢慢处理,以减小系统的压力==。
- Kafka 之所以能从一众消息队列实现中脱颖而出,一个重要的原因就是,==它针对消息写入做了优化,它的生产者写入速度特别快。从整体的表现上看,就是吞吐能力特别强==。
- 好,我们已经对 Kafka 的能力有了一个初步的认识。显然,介绍接口和模型不足以将它与其他消息队列实现区分开来。所以,我们必须拉开大幕,开始去了解它的实现。
软件的结构
- 前面我提到,当我们想去看一个软件的实现时,有两件事特别重要:软件的结构和关键的技术。
- 我们先来看软件的结构。软件的结构其实也是软件的模型,只不过,它不是整体上的模型,而是展开实现细节之后的模型。我在第 1 讲也说过,模型是分层的。
- 对于每个软件来说,当你从整体的角度去了解它的时候,它是完整的一块。但当你打开它的时候,它就变成了多个模块的组合,这也是所谓“分层”的意义所在。而上一层只要使用下一层提供给它的接口就好。
- 所以,当我们打开了一个层次,了解它的实现时,也要先从大处着手。最好的办法就是我们能够找到一张结构图,准确地了解它的结构。
- 如果你能够找到这样一张图,你还是很幸运的。因为在真实的项目中,你可能会碰到各种可能性:
- 结构图混乱:你找到一张图,上面包含了各种内容。比如,有的是模块设计,有的是具体实现,更有甚者,还包括了一些流程;
- 结构图复杂:一个比较成熟的项目,图上画了太多的内容。确实,随着项目的发展,软件解决的问题越来越多,它必然包含了更多的模块。但对于初次接触这个项目的我们而言,它就过于复杂了;
- 无结构图:这是最糟糕的情况,你最好先想办法画出一张图来。
- 无论遇到上述的哪种情况,你了解项目都不会很顺利。所以,你还是要先了解模型和接口,因为它们永远是你的主线,可以帮你从混乱的局面中走出来。
- 那么,假设现在你有了一张结构图,在我们继续前进之前,我想先问一个问题:现在你有了一张结构图,你打算做什么?你可能会问,难道不是了解它的结构吗?是,但不够。我们不仅要知道一个设计的结果,最好还要推断出设计的动因。
- 所以,一种更好的做法是,带着问题上路。我们不妨假设自己就是这个软件的设计者,问问自己要怎么做。然后再去对比别人的设计,你就会发现,自己的想法和别人想法的相同或不同之处。对于理解 Kafka 而言,第一个问题就是如果你来设计一个消息队列,你会怎么做呢?
- 如果在网上搜索 Kafka 的架构图,你会搜到各种各样的图,上面包含了不同的信息。有的告诉你分区(Partition)的概念,有的告诉你 Zookeeper。根据前面对模型的介绍,我特意挑了一张看上去最简单的架构图,因为它最贴近消息队列的基础模型:
- 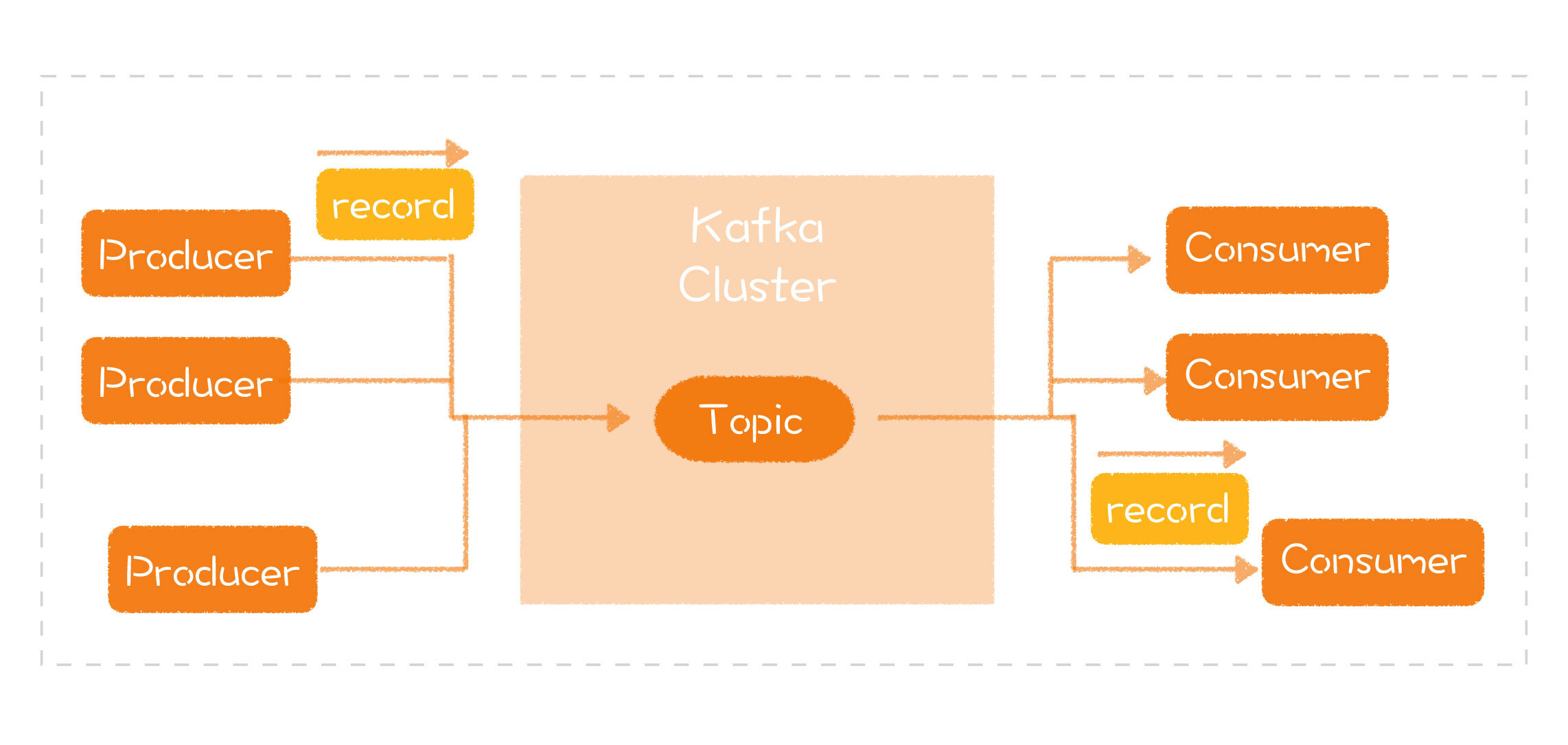
- 那么,从这个图中,你能看到什么呢?你能看到,Kafka 的生产者一端将消息发送给 Kafka 集群,然后,消费者一端将消息取出来进行处理。这样的结构和你想的是不是一样的呢?如果让你负责进一步设计,你会怎么做呢?
- 生产者端封装出一个 SDK,负责消息的发送;
- 消费者端封装出一个 SDK,负责消息的接收;
- 设计一个集群系统,作为生产者和消费者之间的连接。
- 然后,你就可以问自己更多的问题:
- 生产端如果出现网络抖动,消息没有成功发送,它要怎么重试呢?
- 消费端处理完的消息,怎样才能保证集群不会重复发送呢?
- 为什么要设计一个集群呢?要防止出现单点的故障,而一旦有了集群,就会牵扯到下一个问题,集群内的节点如何保证消息的同步呢?
- 消息在集群里是怎么存储的?
- 生产端也好,消费端也罢,如果一个节点彻底掉线,集群该怎么处理呢?
- 你有了更多的问题之后,你就会在代码里进行更深入地探索。你可以根据需要,打开对应模块,进一步了解里面的实现。比如,消息重发的问题,你就可以看看生产端是怎么解决这些问题的。当问题细化到具体实现时,我们就可以打开对应的源码,去里面寻找答案。
- 从结构上来说,Kafka 不是一个特别复杂的系统。所以,如果你的项目更复杂,层次更多,我建议你把各个层次逐一展开,先把整体结构放在心中,再去做细节的探索。
关键的技术
- 我们再来看看理解实现的另一个重要方面:关键技术。
- 什么算是关键技术呢?就是能够让这个软件的“实现”与众不同的地方。了解关键技术可以保证一点,就是我们对代码的调整不会使项目出现明显的劣化。幸运的是,大多数项目都会愿意把自己的关键技术讲出来,所以,找到这些信息并不难。
- 以 Kafka 为例,前面说过,它针对写入做了优化,使得它的整体吞吐能力特别强。那它是怎么做到的呢?
- 消息队列实现消息存储的方式通常是把它写入到磁盘中,而 Kafka 的不同之处在于,==它利用了磁盘顺序读写的特性。对于普通的机械硬盘而言,如果是随机写,需要按照机械硬盘的方式去寻址,然后磁头做机械运动,写入速度就会慢得多。但顺序写的话,会大幅度减少磁头的运动,效率自然就得到了大幅度的提高==。
- 之所以可以这样实现,是充分利用了消息队列本身的特性:有序。它是技术实现与需求完美结合的产物。有了这个基础,就可以有进一步的优化。比如,利用内存映射文件减少用户空间到内核空间复制的开销。
- 如果站在了解实现的角度,你会觉得非常地自然。但要想从设计的角度学到更多,我们还是应该带着问题上路,多问自己一个问题,为什么其他的消息队列之前不这么做呢?这是一个值得深思的问题。Kafka 这个实现到底是哪里不容易想到呢?答案是软硬结合。
- 之前的消息队列实现也会把消息写入到文件里,但文件对它们来说,只是一个通用的接口。开发者并没有想过利用硬件的特性做开发。而 Kafka 的开发者突破了这个限制,把硬件特性利用了起来,从而取得了更好的结果。
- 一旦理解了这一点,我们再来看其他的一些设计,就能学到更多的东西。比如,有一个著名的开源项目LMAX Disruptor,它号称是最强劲的线程通信库。它有一段非常奇怪的代码,类似这样:
- protected long p1, p2, p3, p4, p5, p6, p7;
- 以正常程序员的标准,这简直是无厘头的低劣代码。而想要理解这段代码,你必须理解 CPU 缓存行的机制,这也是一种软硬结合的思路。
- 对于习惯写”软“件的程序员而言,在软件上投入的努力到达极限时,软硬结合是一种思路上的突破。当然,这种突破的前提是要对硬件的机制有所了解,这往往是很多程序员在基本功上欠缺的,可以学习一下计算机组成原理之类的课程。如果你有时间去学习,《深入理解计算机系统》一书值得一读。
- 
程序设计语言
模型
- 背景问题
- > 面向对象用来组织程序是好,但我用的是 C 语言;
> 我用的是 C++,函数式编程的好,跟我有什么关系;
> 动态语言那些特性很好,可惜我用的是 Java;
> ……
- 如果你这么想,说明你被自己的看家本事给局限住了
- 这种思维方式会让 __你即便学到了更多的好东西, 也只能无可奈何__
- >[!tip]
> AndrewHunt 和 DavidThomas在《程序员修炼之道》(The Pragmatic Programmer) 中给程序员们提了一项重要的建议: **每年至少学习一门新语言**
- 程序设计语言本身也是一个软件
- 包含模型、接口和实现
- 我们学习程序设计语言主要是**为了学习程序设计语言提供的编程模型**, 即 ==编程模型 == 思考方式==
- ==不同的程序组织方式 / 不同的控制结构== 等等
- 发展简史 [slightly]
- 一切语法都是语法糖(Syntacticsugar)
- 语法糖是英国计算机科学家 彼得·兰丁 发明的一个术语,指的是那些为了方便程序员使用的语法,它对语言的功能没有影响
- __学习程序设计语言其实就是要学习语言提供的编程模型__, 不提供新编程模型的语言是不值得刻意学习的
- 学习新语言,只是在做增量的学习,思维负担并没有那么沉重。一旦对于程序设计语言的模型有了新的认识,你就能理解一件事:一切语法都是语法糖
- 例如
- C 语言提供了对汇编指令直接的封装。
- C++ 先是提供了面向对象,后来又提供了泛型编程。
- Java 把内存管理从开发者面前去掉了,后来引入的 Annotation 可以进行声明式编程。
- Ruby 提供了动态类型,以及由 Ruby on Rails 引导出的 DSL 风格。
- Scala 和 Clojure 提供了函数式编程。
- Rust 提供了新的内存管理方式,而 Libra 提供的 Move 语言则把它进一步抽象成了资源的概念。
- 要想更好地理解程序设计语言,一种好的做法 -> __打开语法糖, 了解一下语法是怎么实现的__
- 类型是一种对内存的解释方式。
- class/struct 是把有相关性的数据存放到一起的一种数据组织方式。
- Groovy、Scala、Kotlin、Clojure 等 JVM 上的新语言,提供了一种不同于 Java 的封装 JVM 的方式。
- ……
- >[!note]
> 今后再学习一门 [[lang-programming]] 的时候, 多看看语法糖, 多看看语法糖怎么实现的, 为什么这么实现, 解决了哪几方面的问题!!!
接口
- 学习一门新语言,首先是学习语法(Syntax),然后学习程序库(Library),之后再学习运行时(Runtime),这样,你就具备一门语言的基础了。再往后,你需要了解的就是各种惯用法(Idiom),以及如何运用到实际的工作中
- 程序库 (Library)
- 函数 => 最开始的重复是指令级别的重复,程序员们会把同样的指令序列放到一起,通过传入不同的参数进行识别
- 消除重复,也是软件设计的初衷
- 有一些程序库实在是太常用了,它们就会随着语言一起发布,成为标准库
- 程序员熟知的第一个程序“Hello, world”的做法来自《C 程序设计语言》,其中用到的 printf 就是来自 C 的标准库
- Java 程序员无人不知的 JDK,里面包含了大量的程序库
- 在标准库的基础上,再做一次封装,提供一个新的编程模型,或是新的接口,甚至修正一些标准库的bug,让开发变得更简单。只要是人气足够的语言,在这个方面做得都非常好,它们会提供大量的第三方库。
- 正是因为第三方库的兴起,怎样管理第三方库就成了一个问题。今天,这已经成了一个标准的问题,也有了标准的解决方案,那就是包管理器。
- Java的Maven
- Node的NPM
- Ruby的RubyGems
- 像Rust这样年轻的语言,包管理器甚至变成了随语言的发行包一起发布的一项内容
- 如果你已经能够完成基本功能的开发,想让自己在编程水平上再进一步,成为一个更好的程序员,你就可以从封装程序库开始练习。因为想封装出一个好的程序库所需的能力,就是软件设计所需的能力
- 语法
- 一旦变成了语法,它就成了语言的一部分,成为了一个特定的模型, 对于使用者而言,这个模型就是一个接口,只要接口的行为不变,代码就不用变
- 一个经过验证的模式最终变成了语言的一部分,而它的起点只是一个常见的用法:一个程序库
- 程序库配合使用的构造函数往往有一个致命伤,那就是它只有一个名字,也就是类的名字。当我们需要表达多种不同的构造逻辑时,各村就出现了各村的高招。
- 重载(overload), 不同的构造逻辑用不同类型的参数, 一个用HashMap,一个用TreeMap, 作为一个新加入项目的程序员,你很难想到这是两种不同的构造逻辑,它们与这里不同类型的数据结构其实一点关系都没有。
- [[工厂模式]] 解决这个问题,也就是说,用一个名字更能表意的函数,代替构造函数作为构造入口, 从语义上来说,这种做法更清晰
- Java领域的行业名著《EffectiveJava》(第三版)的第一个条款是“用静态工厂方法代替构造函数”,讨论的就是这种做法。
- > Andrew Koenig 和 Barbara Moo 写过一本书《C++ 沉思录》,书里记录了 C++ 早期开发者在设计各种 C++ 特性时的思考,这是一本编程思想之作。当年读这本书时,有两章的标题让我陷入了沉思,分别是**“语言设计就是程序库设计”和“程序库设计就是语言设计”**
- 常是先有程序库,再有语法;如果语法不够好,新的程序库就会出现,新一轮的编程模型就开始孵化。
- 一切有生命力的语言都会不断改善自己的语法,某些好用的程序库就可以转正成为语法。
- Java引入Lambda,支持函数式编程;C++引入类型推演,简化了代码编写
- 同样地,程序库的发展也在推动着语言的不断进步,有一部分语法就是为了让程序库表现得更好而存在的。
- C里面的宏,虽然很多人用它来定义常量,但只有编写程序库才能让它更好地发挥出自身的价值;
- Java中的Annotation,很多人都在用,但用它做过设计的人却很少,因为它的使用场景是以程序库居多;
- Scala中的隐式转换,如果你没有设计过DSL,很可能根本就不知道它有什么具体的作用。
- 想要自己的编程水平上一个台阶,学习编写程序库是一个很好的路径
- 锻炼自己从日常工作中寻找重复
- 更好地理解程序设计语言提供的能力
实现
- 运行时
- 运行时 / 运行时系统 / 运行时环境,它主要是为了实现程序设计语言的执行模型。
- 软件设计的地基, 而不是程序设计语言本身
- 程序运作
- 可执行文件结构
- 程序加载(内存布局)
- 程序动态申请的内存都在堆上,为了支持方法调用要有栈,还要有区域存放我们加载过来的程序,诸如方法区等等
- 指令执行
- 信息
- 运行时给我们提供的接口
- 提供方式
- 标准库
- 动态代理 ( JDK 文档)
- 规范
- 字节码
- 有的程序库给 Java 语言扩展 AOP(Aspect-oriented programming,面向切面编程)的能力
- 程序的极限就不再是语言本身,而是字节码的极限
- 作用
- 有了对于运行时的理解,我们甚至可以做出语言本身不支持的设计
- 运行时的知识很长一段时间内都不是显学,我初学编程时,这方面的资料并不多。不过,近些年来,这方面明显得到了改善,各种程序设计语言运行时的资料开始多了起来。尤其在Java社区,JVM相关的知识已经成为很多程序员面试的重要组成部分。没错,JVM就是一种运行时
DSL
- 领域特定语言
- 一种用于某个特定领域的程序设计语言
- 缩短问题和解决方案之间的距离,降低理解的门槛
- 类型
- 外部DSL
- 内部DSL 将意图与实现分离开
- 区别在于宿主语言
- 常见DSL
- 正则表达式: 一种用于文本处理这个特定领域的DSL
- 配置文件
- 根据需求对软件的行为进行定制
- 以Ngnix为典型
- 单独做Web服务器
- 做反向代理
- 做负载均衡
编程范式
12 | 编程范式:明明写的是Java,为什么被人说成了C代码?
在开始之前,我先给你讲一个小故事。
在一次代码评审中,小李兴致勃勃地给大家讲解自己用心编写的一段代码。这段代码不仅实现了业务功能,还考虑了许多异常场景。所以,面对同事们提出的各种问题,小李能够应对自如。
在讲解的过程中,小李看到同事们纷纷点头赞许,心中不由得生出一丝骄傲:我终于写出一段拿得出手的代码了!讲解完毕,久久未曾发言的技术负责人老赵站了起来:“小李啊!你这段代码从功能上来说,考虑得已经很全面了,这段时间你确实进步很大啊!”
要知道,老赵的功力之深是全公司人所共知的。能得到老赵的肯定,对小李来说,那简直是莫大的荣耀。还没等小李窃喜的劲过去,老赵接着说了,“但是啊,写代码不能只考虑功能,你看你这代码写的,虽然用的是 Java,但写出来的简直就是 C 代码。”
正在兴头上的小李仿佛被人当头泼了一盆冷水,我用的是 Java 啊!一门正经八百的面向对象程序设计语言,咋就被说成写的是 C 代码了呢?
“你看啊!所有的代码都是把字段取出来计算,然后,再塞回去。各种不同层面的业务计算混在一起,将来有一点调整,所有的代码都得跟着变。”老赵很不客气地说。还没缓过神来的小李虽然想辩解,但他知道老赵说得是一针见血,指出的问题让人无法反驳。
在实际的开发过程中,有不少人遇到过类似的问题。老赵的意思并不是小李的代码真就成了 C 代码,而是说用 Java 写的代码应该有 Java 的风格,而小李的代码却处处体现着 C 的风格。
那这里所谓代码的风格到底是什么呢?它就是编程范式。
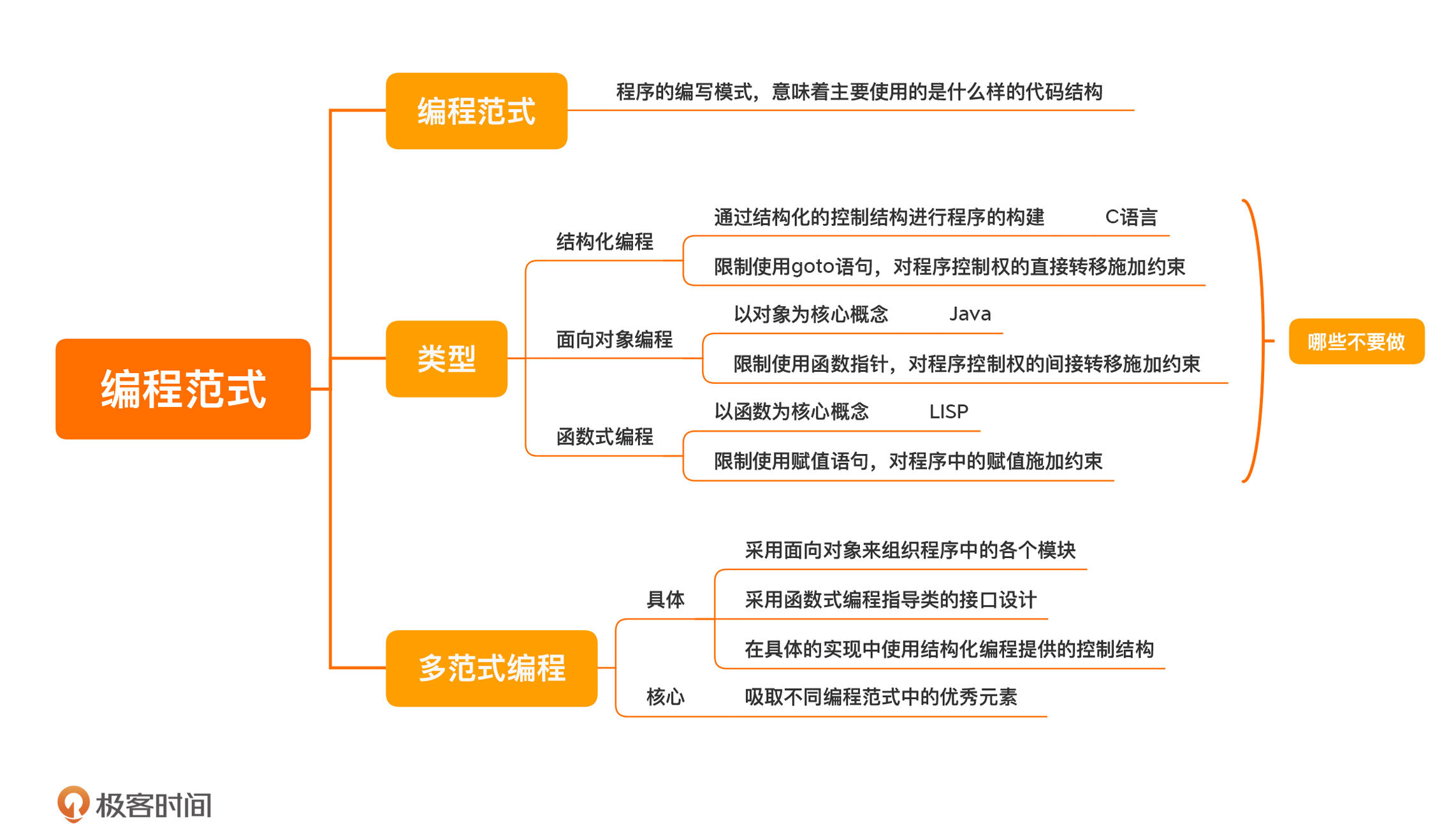
- 编程范式(Programming paradigm),指的是程序的编写模式。==使用了什么编程范式,通常意味着,你主要使用的是什么样的代码结构==。从设计的角度说,编程范式决定了你在设计的时候,可以使用的元素有哪些。
- 现在主流的编程范式主要有三种:
- 结构化编程(structured programming);
- 结构化编程,是大部分程序员最熟悉的编程范式,它通过一些结构化的控制结构进行程序的构建。你最熟悉的控制结构应该就是 if/else 这样的选择结构和 do/while 这样的循环结构了。
- 结构化编程是最早普及的编程范式,现在最典型的结构化编程语言是 C 语言。C 语言控制结构的影响极其深远,成为了很多程序设计语言的基础。
- 面向对象编程(object-oriented programming);
- 面向对象编程,是现在最主流的编程范式,它的核心概念就是对象。用面向对象风格写出的程序,本质上就是一堆对象之间的交互。面向对象编程给我们提供了一种管理程序复杂性的方式,其中最重要的概念就是多态(polymorphism)。
- 现在主流的程序设计语言几乎都提供面向对象编程能力,其中最典型的代表当属 Java。
- 函数式编程(functional programming)。
- 函数式编程,是近些年重新崛起的编程范式。顾名思义,它的核心概念是函数。但是,它的函数来自于数学里面的函数,所以,和我们常规理解的函数有一个极大的不同:不变性。也就是说,一个符号一旦创建就不再改变。
- 函数式编程的代表性语言应该是 LISP。我们在第 8 讲曾经提到过它。之所以要把这位老祖宗搬出来,因为确实还没有哪门函数式编程语言能够完全独霸一方。
- 编程范式不仅仅是提供了一个个的概念,更重要的是,它对程序员的能力施加了约束。
- ==结构化编程,限制使用 goto 语句,它是对程序控制权的直接转移施加了约束。==
- ==面向对象编程,限制使用函数指针,它是对程序控制权的间接转移施加了约束。==
- ==函数式编程,限制使用赋值语句,它是对程序中的赋值施加了约束。==
- 之后讲到具体的编程范式时,我们再来展开讨论,这些约束到底是什么意思。
- 与其说这些编程范式是告诉你如何编写程序,倒不如说它们告诉你不要怎样做。理解这一点,你才算是真正理解了这些编程范式。
- 如果你去搜索编程范式的概念,你可能会找到更多的编程范式,比如,逻辑式编程,典型的代表是 Prolog 语言。但这些编程范式的影响力和受众面都相当有限。如果你想扩展自己的知识面,可以去了解一下。
多范式编程
- 从道理上讲,编程范式与具体语言的关系不大,这就好比你的思考与用什么语言表达是无关的。但在实际情况中,每一种语言都有自己的主流编程范式。比如,C 语言主要是结构化编程,而 Java 主要是面向对象编程。
- 不过,虽然每种语言都有自己的主流编程范式,但丝毫不妨碍程序员们在学习多种编程范式之后,打破“次元壁”,将不同编程范式中的优秀元素吸纳进来。这里的重点是“优秀”,而非“所有”。
- 举个例子,在 Linux 的设计中,有一个虚拟文件系统(Virtual File System,简称 VFS)的概念,你可以把它理解成一个文件系统的接口。在所有的接口中,其中最主要的是 file\_operations,它就对应着我们熟悉的各种文件操作。
- 下面是这个结构的定义,这个结构很长,我从中截取了一些我们最熟悉的操作:
struct file_operations {
loff_t (*llseek) (struct file *, loff_t, int);
ssize_t (*read) (struct file *, char __user *, size_t, loff_t *);
ssize_t (*write) (struct file *, const char __user *, size_t, loff_t *);
int (*open) (struct inode *, struct file *);
int (*flush) (struct file *, fl_owner_t id);
int (*release) (struct inode *, struct file *);
...
- 如果你要开发一个自己的文件系统,只需要把支持的接口对应着实现一遍,也就是给这个结构体的字段赋值。
- 我们换个角度看,这个结构体主要的字段都是函数指针,文件系统展现的行为与这些函数的赋值息息相关。只要给这个结构体的字段赋值成不同的参数,也就是把不同的函数关联上,这个文件系统就有了不同的行为。如果熟悉面向对象编程,你会发现,这不就是多态吗?
- C 是一门典型的结构化编程语言,而 VFS 的设计展现出来的却是面向对象编程的特点,编程范式的“次元壁”在这里被打破了。
- 事实上,类似的设计还有很多,比如,Java 里有一个著名的基础库,Google 出的 Guava。它里面就提供了函数式编程的基础设施。在 Java 8 之前,Java 在语法上并不支持函数式编程,但这并不妨碍我们通过类模拟出函数。
- 配合着 Guava 提供的基础设施,我很早就开始把函数式编程的方式运用在 Java 中了。同样,C++ 有一个 functor 的概念,也就是函数对象,通过重载 () 这个运算符,让对象模拟函数的行为。
- 无论是在以结构化编程为主的语言中引入面向对象编程,还是在面向对象为主的语言中引入函数式编程,在一个程序中应用多种编程范式已经成为了一个越来越明显的趋势。
- 不仅仅是在设计中,现在越来越多的程序设计语言开始将不同编程范式的内容融合起来。Java 从 Java 8 开始引入了 Lambda 语法,现在我们可以更优雅地写出函数式编程的代码了。同样,C++ 11 开始,语法上也开始支持 Lambda 了。
- 之所以多范式编程会越来越多,是因为我们的关注点是做出好的设计,写出更容易维护的代码,所以,我们会尝试着把不同编程风格中优秀的元素放在一起。比如,==我们采用面向对象来组织程序,而在每个类具体的接口设计上,采用函数式编程的风格,在具体的实现中使用结构化编程提供的控制结构。==
- 让我们回过头,看看开篇故事小李的委屈吧!老赵之所以批评小李,关键点就是小李并没有把各种编程范式中优秀的元素放到一起。Java 是提供对面向对象的支持,面向对象的强项在于程序的值,它归功的设计元素应该是对象,程序应该是靠对象的组合来完成,而小李去把它写成了平铺直叙的结构化代码,这当然是不值得鼓励的。
- 对于今天的程序员来说,学习不同的编程范式,将不同编程范式中的优秀元素应用在我们日常的软件设计之中,已经由原来的可选项变成了现在的必选项。否则,你即便拥有强大的现代化武器,也只能用作古代的冷兵器。
- 
思考题
- 今天我们谈到了编程范式,每个程序员都会有自己特别熟悉的编程范式,但今天我想请你分享一下,你在学习其他编程范式时,给你思想上带来最大冲击的内容是什么。欢迎在留言区分享你的想法。
- 感谢阅读,如果你觉得这一讲的内容对你有帮助的话,也欢迎把它分享给你的朋友。
13 | 结构化编程:为什么做设计时仅有结构化编程是不够的?
上一讲,我们讲到了编程范式,现在开发的一个重要趋势就是多种编程范式的融合,显然,这就要求我们对各种编程范式都有一定的理解。从这一讲开始,我们就展开讨论一下几个主要的编程范式。首先,我们来讨论程序员们最熟悉的编程范式:结构化编程。
很多人学习编程都是从 C 语言起步的,C 语言就是一种典型的结构化编程语言。C 的结构化编程也渗透进了后来的程序设计语言之中,比如,C++、Java、C# 等等。
说起结构化编程,你一定会想起那些典型的控制结构,比如:顺序结构、选择结构和循环结构,还会想到函数(如果用术语讲,应该叫 subroutine)和代码块(block)。这几乎是程序员们每天都在使用的东西,对于这些内容,你已经熟悉得不能再熟悉了。
但是,不知道你是否想过这样一个问题?面向对象编程之所以叫面向对象,是因为其中主要的概念是对象,而函数式编程主要的概念是函数。可结构化编程为什么叫结构化呢,难道它的主要概念是结构?这好像也不太对。
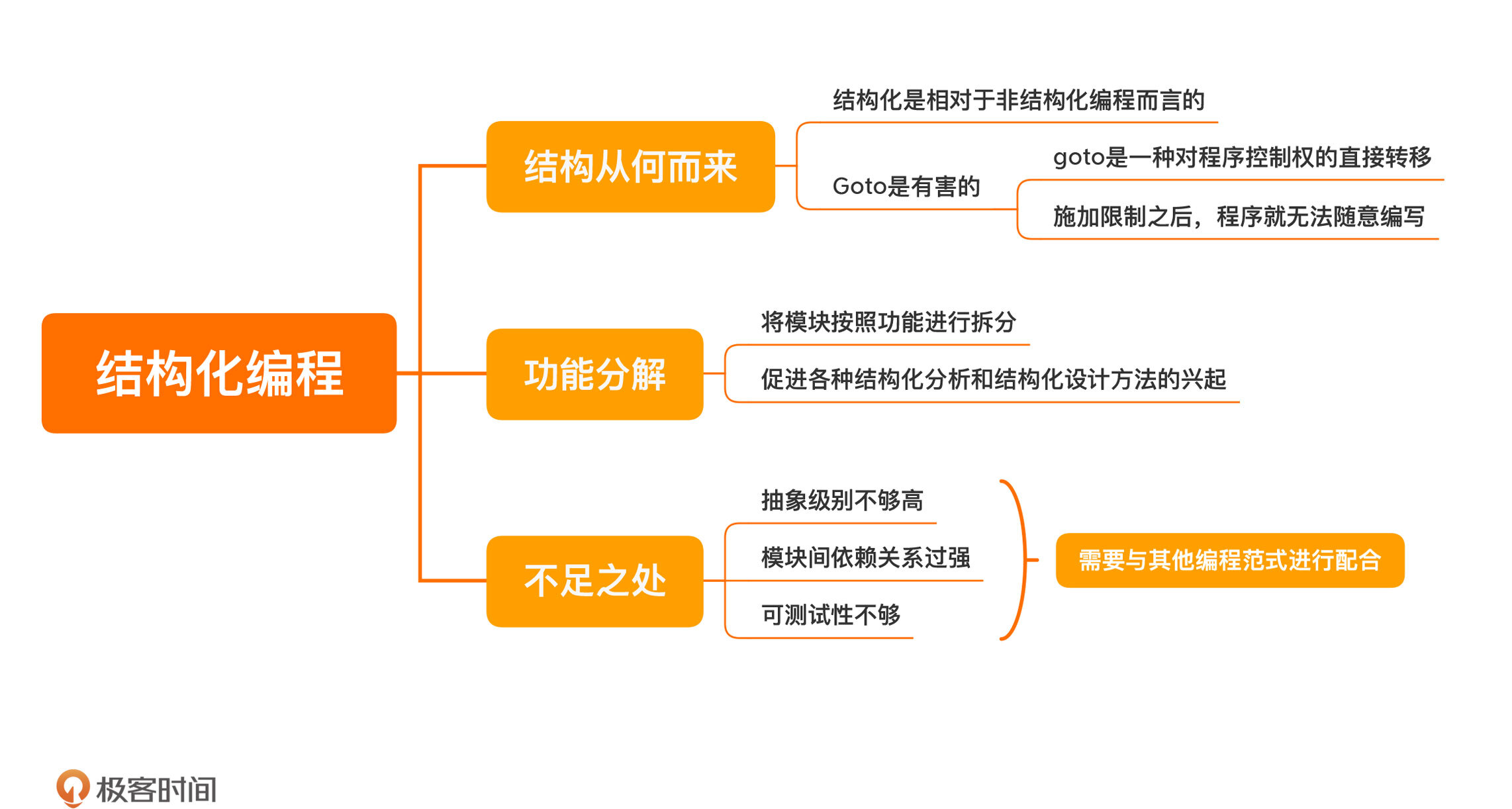
其实,所谓结构化,是相对于非结构化编程而言的。所以,要想真正了解结构化编程,就要回到非结构化的古老年代,看看那时候是怎么写程序的。也就是说,只有了解结构化编程的发展历程,你才能更好地认清结构化编程的不足。
没错,正是因为你太熟悉结构化编程了,我反而要说说它的不足,告诉你在今天做设计,仅仅有结构化编程已经不够了。好,我们就先从结构化编程的演化讲起。
结构从何而来
- 你一定知道,结构化编程中的顺序结构就是代码按照编写的顺序执行,选择结构就是 if/else,而循环结构就是 do/while。这几个关键字一出,是不是就有一股亲切感扑面而来?
- 但是,你有没有想过,这些结构是怎么来的呢?
- 我们都知道,今天的编程语言都是高级语言,那对应着就应该有低级语言。就今天这个讨论而言,比高级语言低级的就是汇编语言。如果你去了解汇编指令,你会发现,它的编程模式与我们习惯的高级语言的编程模式有着很大的差异。
- 使用汇编写代码,你面对的是各种寄存器和内存地址。那些我们在高级语言中经常面对的变量,需要我们自己想办法解决,而类型,则统统没有。至于前面提及的那些控制结构,除了顺序结构之外,在汇编层面也是不存在的。
- 连 if/else 和 do/while 都没有,让我怎么写程序啊?
- 别急,在汇编里有个 goto,它可以让代码跳转到另外一个地方继续执行。还有几个比较指令,让你可以比较两个值。
- 我们先想一下, if 语句做的是什么呢?执行一个表达式,然后,根据这个表达式返回值是真是假,决定执行 if 后面的代码,还是 else 后面的代码。
- 好,如果我们这么写汇编代码,就是先执行一段代码,把执行结果和 0 比较。如果不等于 0 就接着执行,等于 0 就跳转到另外一个地方执行,这不就和 if 语句的执行逻辑是一样的吗?
- 没错,如果你尝试反汇编一段有 if 语句的 C 代码,也会看到类似的汇编代码。如果你是一个 Java 程序员,也可以通过 javap 反汇编一段 Java 类,也可以看到类似的字节码,因为字节码在 Java 里就相当于汇编。
- 
- 有了对 if 语句的理解,再来理解 while/for 就容易了,就是在判断之后,是决定跳到另外一个地方,还是继续执行下面的代码。如果执行下面的代码,执行到后面就会有一个 goto 让我们跳回来,再作一次判断。
- 了解这些,再加上汇编语言本身的顺序执行,你最熟悉的控制结构就都回来了。所以,即便是用汇编,你依然可以放心地以原来的方式写代码了。
- 对于已经有了编程基础的你而言,理解这些内容并不难。但你有没有想过,以前的程序员真的就是用这样的控制结构写程序的吗?并不是。
- 原来的程序员面对的的确是这些汇编指令,但是他们是站在直接使用指令的角度去思考。所以,他们更习惯按照自己的逻辑去写,这其中最方便的写法当然就是需要用到哪块逻辑,就 goto 到哪里执行一段代码,然后,再 goto 到另外一个地方。
- 这种写起来自由自在的方式,在维护起来却会遇到极大的挑战,因为你很难预测代码的执行结果。有人可能只是图个方便,就 goto 到一个地方继续执行。可只要代码规模稍微一大,就几乎难以维护了,这便是非结构化的编程方式。
Goto 是有害的
- ==于是,有人站了出来,提出编程要有结构,不能这么肆无忌惮,结构化编程的概念应运而生。==这其中有个重要人物,你一定听说过,叫迪杰斯特拉(Dijkstra),他是 1972 年的图灵奖的获得者。
- 学习算法的时候,你肯定学过以他名字命名的最短路算法;学习操作系统时,你肯定学过 PV 原语,==PV 原语这个名字之所以看起来有些奇怪,主要因为 Dijkstra 是荷兰人。==
- ==1968 年,他在 ACM 通讯上发表了一篇文章,题目叫做《Goto 是有害的》(Go To Statement Considered Harmful),这篇文章引起了轩然大波。==
- 不是所有人都会接受这种新想法,那些习惯了自由放纵的程序员对 Dijkstra 进行了无情的冷嘲热讽。他们认为,按照结构化的方法写效率太低。今天的你可能很难想象,C 语言初问世之际,遭到最大的质疑是效率低。对,你没听错,C 语言被质疑效率低,和 Java 面世之初遇到的挑战如出一辙。
- 提出这种质疑的人只看到了新生事物初生时的不足,却忽略了它们强大的可能性。==他们不知道,一旦构建起新的模型,底层实现是可以不断优化的==。
- 更重要的是,有了新的更高级却也更简单的模型,入门门槛就大幅度降低了,更多的人就可以加入进来,进一步促进这门语言的发展。程序员数量的增多,就可以证明这一点。
- 现在的很多程序员其实对底层知识的了解并不多,但丝毫不妨碍他们完成基本的业务功能。只要使用的人足够多,人们就会有更强的驱动力去优化底层实现。时至今日,已经很少有人敢说自己手写的汇编性能一定优于编译器优化后的结果。
- 最终这场争论逐渐平息,新的结构逐渐普及,也证明了 Dijkstra 是对的。goto 语句的重要性逐渐降低,一些现代程序设计语言干脆在设计上就把 goto 语句拿掉了。
功能分解
- 你可能没有想过,这种结构化编程的思想最初是为了证明程序正确性而诞生的。
- Dijkstra 很早就得出一个结论:编程是一项难度很大的活动。因为一个程序会包含非常多的细节,远超一个人的认知能力范围,任何一个细微的错误都会导致整个程序出现问题。
- 所以,他提出 goto 语句是有害的,还有一个重要的原因是,Dijkstra 为了证明程序的正确性,在借助数学推导的方法,将大问题拆分成小问题,逐步递归下去,拆分成更小的、可证明的单元时,==他发现 goto 语句的存在影响了问题的递归拆分,导致问题无法被拆分。==
- 你也许看出来了,我要说的就是结构化编程另一个重要的方面:功能分解。
- [ ] #gtd/todo ==AI 是怎么做功能分解的呀?==
- 功能分解就是将模块按照功能进行拆分。这样一来,一个大问题就会被拆解成一系列高级函数的组合,而这些高级函数各自再进一步拆分,拆分成一系列的低一级的函数,如此一步步拆分下去,每一个函数都需要按照结构化编程的方式进行开发。这一思想符合人们解决问题的直觉,对软件开发产生了深远的印象。
- 以此为基础,后来出现各种结构化分析和结构化设计的方法。将大型系统拆分成模块和组件,这些模块和组件再做进一步的拆分,这些都是来自结构化编程的设计思想。在今天看来,这一切简直再正常不过了,几乎融入了每个程序员的日常话语体系之中。
- 好,说完了结构化编程的发展历程,我们自然也就能看出它的不足之处了。
- 虽然,结构化编程是比汇编更高层次的抽象,程序员们有了更强大的工具,但人们从来不会就此满足,随之而来的是,程序规模越来越大。这时,结构化编程就显得力不从心了。用一个设计上的说法形容结构编程就是“抽象级别不够高”。
- 这就好比你拿着一个显微镜去观察,如果你观察的目标是细菌,它能够很好地完成工作,但如果用它观察一个人,你恐怕就很难去掌握全貌了。==结构化编程是为了封装低层的指令而生的,而随着程序规模的膨胀,它组织程序的方式就显得很僵硬,因为它是自上而下进行分解的。==
- ==一旦需求变动,经常是牵一发而动全身,关联的模块由于依赖关系的存在都需要变动,无法有效隔离变化。==显然,如何有效地组织这么大规模的程序并不是它的强项,所以,结构化编程注定要成为其它编程范式的基石。
- 如果站在今天的角度看,结构化编程还存在一个问题,就是==可测试性不够,道理和上面是一样的,它的依赖关系太强,很难拆出来单独测试一个模块。==
- 所以,仅仅会结构化编程,并不足以让我们做出好的设计,必须把它与其他编程范式结合起来,才能应对已经日益膨胀的软件规模。
- 
思考题
- Dijkstra 在结构化编程这件事上的思考远远大于我们今天看到的样子。你是否也有这样的经历,你在学习哪门技术时,了解到其背后思想之后,让你觉得受到了很大的震撼。欢迎在留言区分享你的想法。
- 感谢阅读,如果你觉得这一讲的内容对你有帮助的话,也欢迎把它分享给你的朋友。
14 | 面向对象之封装:怎样的封装才算是高内聚?
这一讲,我们先从封装说起。
上一讲,我讲了你最熟悉的编程范式:结构化编程。结构化编程有效地解决了过去的很多问题,它让程序员们解决问题的规模得以扩大。
随着程序规模的逐渐膨胀,结构化编程在解决问题上的局限也越发凸显出来。因为在它提供的解决方案中,各模块的依赖关系太强,不能有效地将变化隔离开来。这时候,面向对象编程登上了大舞台,它为我们提供了更好的组织程序的方式。
在一些从结构化编程起步的程序员的视角里,面向对象就是数据加函数。虽然这种理解不算完全错误,但理解的程度远远不够。结构化编程的思考方式类似于用显微镜看世界,这种思考方式会让人只能看到局部。而想要用好面向对象编程,则需要我们有一个更宏观的视角。
谈到面向对象,你可能会想到面向对象的三个特点:封装、继承和多态。在接下来的三讲,我们就分别谈谈面向对象的这三个特点。
也许你会觉得,学面向对象程序设计语言的时候,这些内容都学过,没什么好讲的。但从我接触过的很多程序员写程序的风格来看,大多数人还真的不太理解这三个特点。还记得我们在第 12 讲中提到的那个故事吗?小李之所以被老赵批评,主要就是因为他虽然用了面向对象的语言,代码里却没有体现出面向对象程序的特点,没有封装,更遑论继承和多态。
嘴上说得明明白白,代码写得稀里糊涂,这就是大多数人学习面向对象之后的真实情况。所以,虽然看上去很简单,但还是有必要聊聊这些特点。
理解封装
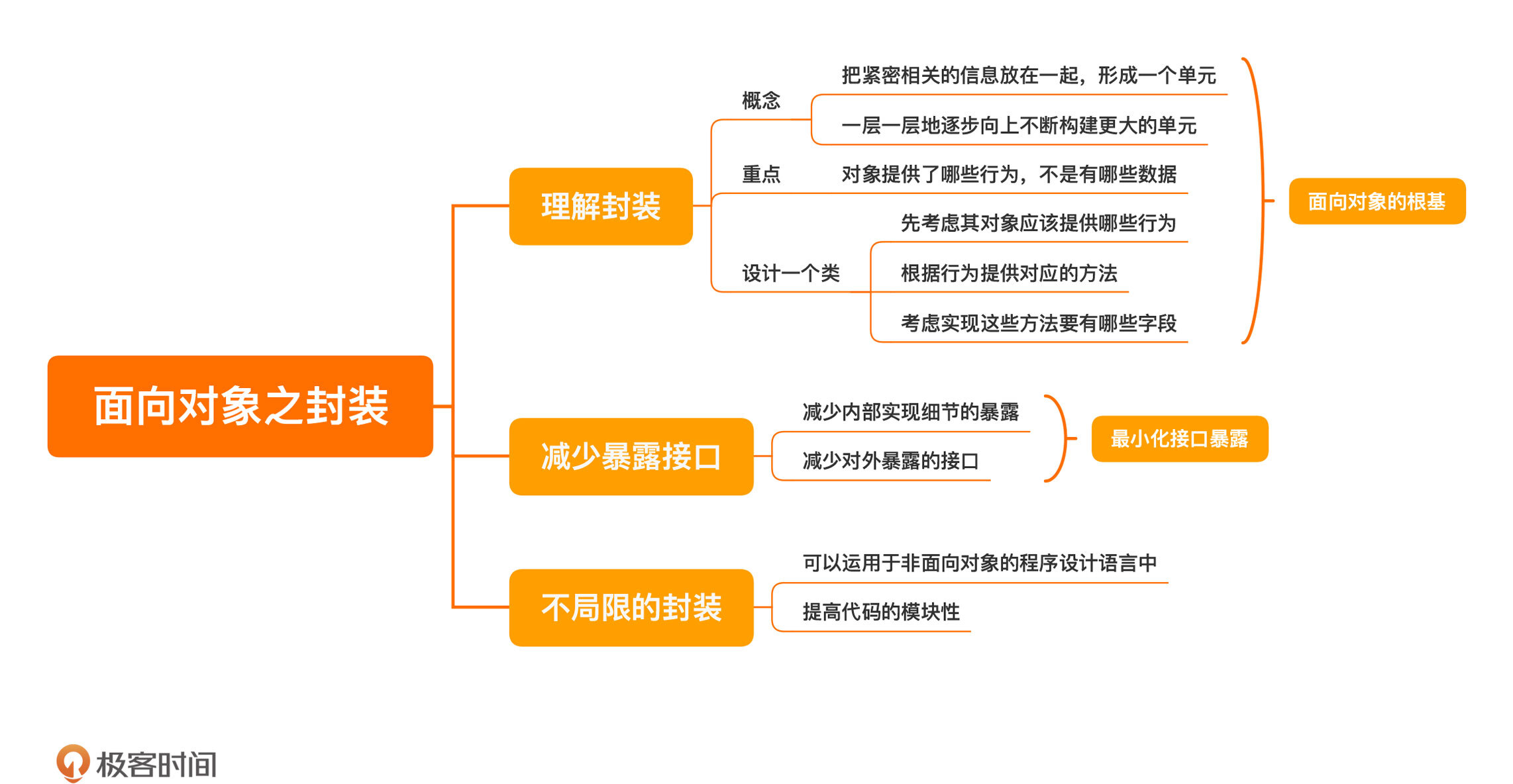
- 我们知道,面向对象是解决更大规模应用开发的一种尝试,它提升了程序员管理程序的尺度。
- 封装,则是面向对象的根基。它把紧密相关的信息放在一起,形成一个单元。如果这个单元是稳定的,我们就可以把这个单元和其他单元继续组合,构成更大的单元。然后,我们再用这个组合出来的新单元继续构建更大的单元。由此,一层一层地逐步向上。
- 为了让你更好地理解这个过程,我们先回到面向对象的最初。
- “面向对象”这个词是由 Alan Kay 创造的,他是 2003 年图灵奖的获得者。在他最初的构想中,对象就是一个细胞。当细胞一点一点组织起来,就可以组成身体的各个器官,再一点一点组织起来,就构成了人体。而当你去观察人的时候,就不用再去考虑每个细胞是怎样的。所以,面向对象给了我们一个更宏观的思考方式。
- 但是,这一切的前提是,每个对象都要构建好,也就是封装要做好,这就像每个细胞都有细胞壁将它与外界隔离开来,形成了一个完整的个体。
- 在 Alan Kay 关于面向对象的描述中,他强调对象之间只能通过消息来通信。如果按今天程序设计语言的通常做法,发消息就是方法调用,对象之间就是靠方法调用来通信的。但这个方法调用并不是简单地把对象内部的数据通过方法暴露。在 Alan Kay 的构想中,他甚至想把数据去掉。
- 因为,==封装的重点在于对象提供了哪些行为,而不是有哪些数据。也就是说,即便我们把对象理解成数据加函数,数据和函数也不是对等的地位。函数是接口,而数据是内部的实现,正如我们一直说的那样,接口是稳定的,实现是易变的==。
- ==数据是二等公民==
- 理解了这一点,我们来看一个很多人都有的日常编程习惯。他们编写一个类的方法是,把这个类有哪些字段写出来,然后,生成一大堆 getter 和 setter,将这些字段的访问暴露出去。==这种做法的错误就在于把数据当成了设计的核心,这一堆的 getter 和 setter,就等于把实现细节暴露了出去。==
- ==一个正确的做法应该是,我们设计一个类,先要考虑其对象应该提供哪些行为。然后,我们根据这些行为提供对应的方法,最后才是考虑实现这些方法要有哪些字段。==
- 请注意,方法的命名,体现的是你的意图,而不是具体怎么做。所以,getXXX 和 setXXX 绝对不是一个好的命名。举个例子,设计一个让用户修改密码的功能,有些人直觉的做法可能是这样:
class User {
private String username;
private String password;
...
public void setPassword(final String password) {
this.password = password;
}
- 但我们鼓励的做法是,把意图表现出来:
class User {
private String username;
private String password;
...
public void changePassword(final String password) {
this.password = password;
}
- 这两段代码相比,只是修改密码的方法名变了,但二者更重要的差异是,一个在说做什么,一个在说怎么做。将意图与实现分离开来,这是一个优秀设计必须要考虑的问题。
- 不过,在真实的项目中,有时确实需要暴露一些数据,所以,等到你确实需要暴露的时候,再去写 getter 也不迟,你一定要问问自己为什么要加 getter。至于 setter,首先,大概率是你用错了名字,应该用一个表示意图的名字;其次,setter 通常意味着修改,这是我们不鼓励的。
- 我后面讲函数式编程时,会讲到不变性,可变的对象会带来很多的问题,到时候我们再来更具体地讨论。所以,设计中更好的做法是设计不变类。
减少暴露接口
- 之所以我们需要封装,就是要构建一个内聚的单元。所以,我们要减少这个单元对外的暴露。这句话的第一层含义是减少内部实现细节的暴露,它还有第二层含义,减少对外暴露的接口。
- 一般面向对象程序设计语言都支持 public、private 这样的修饰符。程序员在日常开发中,经常会很草率地给一个方法加上 public,从而不经意间将一些本来应该是内部实现的部分暴露出去。
- 举个例子,一个服务要停下来的时候,你可能要把一些任务都停下来,代码可能会这样写:
class Service {
public void shutdownTimerTask() {
}
public void shutdownPollTask() {
}
- 别人调用时,可能会这样调用这段代码:
class Application {
private Service service;
public void onShutdown() {
service.shutdownTimerTask();
service.shutdownPollTask();
}
- 突然有一天,你发现,停止轮询任务必须在停止定时器任务之前,你就不得不要求别人改代码。而这一切就是因为我们很草率地给那两个方法加上了 public,让别人有机会看到了这两个方法。
- 从设计的角度来说,我们必须谨慎地问一下,这个方法真的有必要暴露出去吗?
- 就这个例子而言,我们可以仅仅暴露一个方法:
class Service {
private void shutdownTimerTask() {
}
private void shutdownPollTask() {
}
public void shutdown() {
this.shutdownTimerTask();
this.shutdownPollTask();
}
- 我们调用代码也会简单很多:
class Application {
private Service service;
public void onShutdown() {
service.shutdown();
}
- ==尽可能减少接口暴露,这个原则不仅仅适用于类的设计,同样适用于系统设计==。在我的职业生涯中,看到了很多团队非常随意地在系统里面添加接口,一个看似不那么复杂的系统里,随随便便就有成百上千个接口。
- 如果你想改造系统去掉一些接口时,很有可能会造成线上故障,因为你根本不知道哪个团队在什么时候用到了它。所以,在软件设计中,暴露接口需要非常谨慎。
- 关于这一点,你可以有一个统一的原则:==最小化接口暴露==。也就是,每增加一个接口,你都要找到一个合适的理由。
不局限于面向对象的封装
- 虽说封装是面向对象的一个重要特征,但是,当理解了封装之后,你同样可以把它运用于非面向对象的程序设计语言中,把代码写得更具模块性。
- 比如,我们知道 C 语言有头文件(.h 文件)和定义文件(.c 文件),在通常的理解中,头文件放的是各种声明:函数声明、结构体等等。很多 C 程序员甚至有一个函数就在头文件里加一个声明。
- 有了今天对于封装的讲解,再来看 C 语言的头文件,我们可以让它扮演接口的角色,而定义文件就成了实现。根据今天的内容,既然,接口只有相当于 public 接口的函数才可以放到头文件里,那么,在头文件里声明一个函数时,我们首先要问的就是,它需要成为一个公开的函数吗?
- C 语言没有 public 和 private 这样的修饰符,但我曾在一些 C 的项目上加入了自己的定义:
- 然后,我们规定头文件里只能放公有接口,而在实现文件中的每个函数前面,加上了 PUBLIC 和 PRIVATE,以示区分。==这里将 PRIVATE 定义成了 static,是利用了 C 语言 static 函数只能在一个文件中可见的特性。==
- 我们还可以把一个头文件和一个定义文件合在一起,把它们看成一个类,不允许随意在头文件中声明不相关的函数。比如,下面是我在一个头文件里定义了一个点(Point):
struct Point;
struct Point* makePoint(double x, double y);
double distance(struct Point* x, struct Point* y);
- 你可能注意到了,Point 这个结构体我只给了声明,没有给定义。因为我并不希望给它的用户访问其字段的权限,结构体的具体定义是实现,应该被隐藏起来。对应的定义文件很简单,就不在这里罗列代码了。
- 说到这里,你也许发现了,C 语言的封装做得更加彻底。如果用 Java 或 C++ 定义 Point 类的话,必然会给出具体的字段。==从某种程度上来说,Java 和 C++ 的做法削弱了封装性。==
- 讲到这里,你应该已经感受到面向对象和结构化编程在思考问题上的一些差异了。有了封装,对象就成了一个个可以组合的单元,也形成了一个个可以复用的单元。面向对象编程的思考方式就是组合这些单元,完成不同的功能。同结构化编程相比,这种思考问题的方式站在了一个更宏观的视角上。
- 
思考题
- 最后,我想请你了解一下迪米特法则(Law of Demeter),结合今天的课程,分享一下你对迪米特法则的理解。欢迎在留言区分享你的想法。
- 感谢阅读,如果你觉得这一讲的内容对你有帮助的话,也欢迎把它分享给你的朋友。
15 | 面向对象之继承:继承是代码复用的合理方式吗?
上一讲,我们讨论了面向对象的第一个特点:封装。这一讲,我们继续来看面向对象的第二个特点:继承。首先,你对继承的第一印象是什么呢?
说到继承,很多讲面向对象的教材一般会这么讲,给你画一棵树,父类是根节点,而子类是叶子节点,显然,一个父类可以有许多个子类。
父类是干什么用的呢?就是把一些公共代码放进去,之后在实现其他子类时,可以少写一些代码。讲程序库的时候,我们说过,设计的职责之一就是消除重复,代码复用。所以,在很多人的印象中,继承就是一种代码复用的方式。
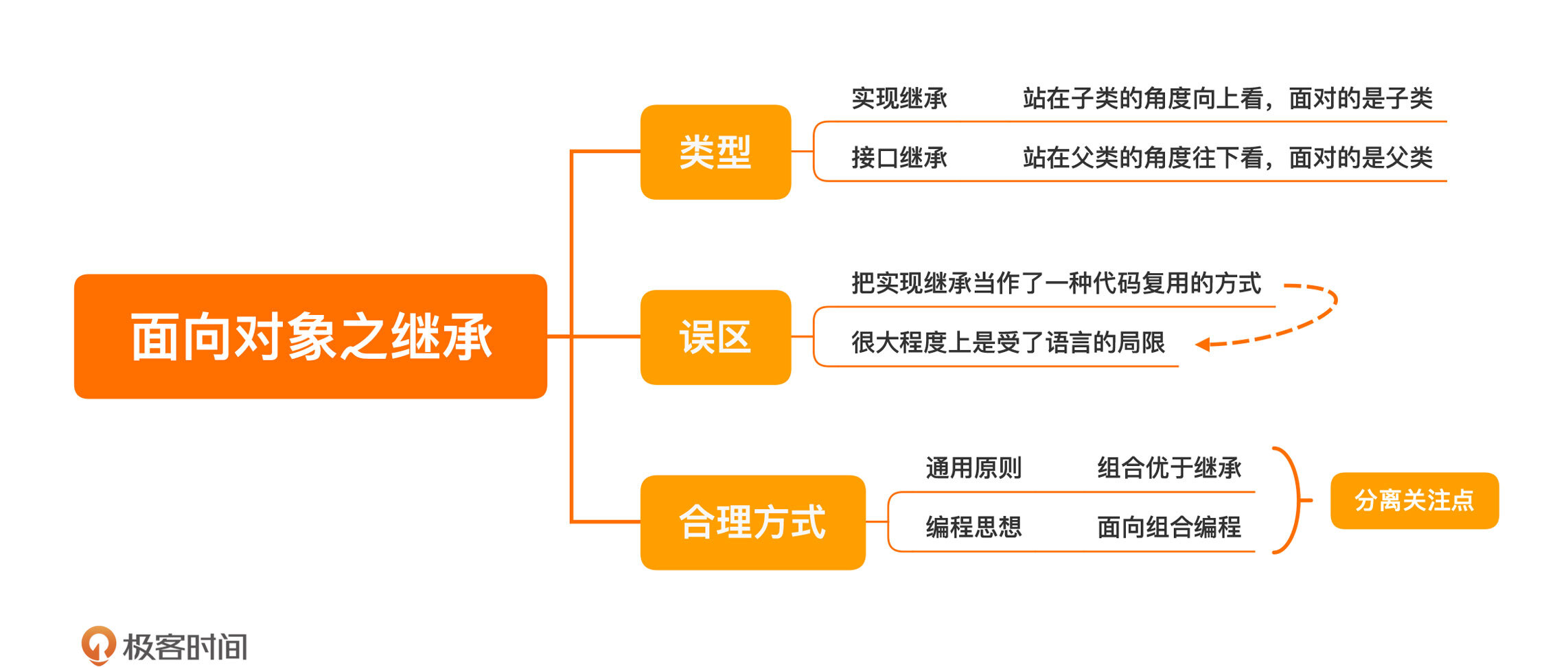
如果我们把继承理解成一种代码复用方式,更多地是站在子类的角度向上看。在客户端代码使用的时候,面对的是子类,这种继承叫实现继承:
Child object = new Child();
其实,还有一种看待继承的角度,就是从父类的角度往下看,客户端使用的时候,面对的是父类,这种继承叫接口继承:
Parent object = new Child();
不过,接口继承更多是与多态相关,我们暂且放一放,留到下一讲再来讨论。这一讲,我们还是主要来说说实现继承。其实,实现继承并不是一种好的做法。
也就是说,把实现继承当作一种代码复用的方式,并不是一种值得鼓励的做法。
一方面,继承是很宝贵的,尤其是 Java 这种单继承的程序设计语言。每个类只能有一个父类,一旦继承的位置被实现继承占据了,再想做接口继承就很难了 。另一方面,实现继承通常也是一种受程序设计语言局限的思维方式,有很多程序设计语言,即使不使用继承,也有自己的代码复用方式。 可能这么说你还不太理解,接下来,我就用一个例子来帮你更好地理解继承。
代码复用
- 假设,我要做一个产品报表服务,其中有个服务是要查询产品信息,这个查询过程是通用的,别的服务也可以用,所以,我把它放到父类里面。
- 这就是代码复用的做法,代码用 Java 写出来是这样的:
class BaseService {
protected List<Product> getProducts(List<String> product) {
...
}
class ReportService extends BaseService {
public void report() {
List<Product> product = getProduct(...);
...
}
- 如果采用 Ruby 的 mixin 机制,我们还可以这样实现,先定义一个模块(module):
module ProductFetcher
def getProducts(products)
...
end
end
- 然后,在自己的类定义中,将它包含(include)进来:
class ReportService
include ProductFetcher
def report
products = getProducts(...)
..
end
end
- 在这个例子中,ReportService 并没有继承任何类,获取产品信息的代码也是可以复用的,也就是这里的 ProductFetcher 这个模块。这样一来,如果我需要有一个获取产品信息的地方,它不必非得是一个什么服务,无需继承任何类。
- 这是 Ruby 的做法,类似的语言特性还有 Scala 里的 trait。
- 在 C++ 中,虽然语法并没有严格地区分实现继承,但《Effective C++》这本行业的名著,给出了一个实用的建议:实现继承采用私有继承的方式实现:
- class ReportService: private ProductFetcher {
- ...
- 请注意,在这个实现里,我的私有继承类名是 ProductFetcher。是的,它并不需要和这个报表服务有什么直接的关系,使用私有继承,就是为了复用它的代码。
- 从前面的分析中,我们也不难看出,获取产品信息和生成报表其实是两件事,只是因为在生成报表的过程中,需要获取产品信息,所以,它有了一个基类。
- 其实,在 Java 里面,我们不用继承的方式也能实现,也许你已经想到了,代码可以写成这样:
- class ProductFetcher {
- public List<Product> getProducts(List<String> product) {
- ...
- }
- class ReportService {
- private ProductFetcher fetcher;
- public void report() {
- List<Product> product = fetcher.getProducts(...);
- ...
- }
- 这种实现方案叫作组合,也就是说 ReportService 里组合进一个 ProductFetcher。在设计上,有一个通用的原则叫做:组合优于继承。也就是说,如果一个方案既能用组合实现,也能用继承实现,那就选择用组合实现。
- 好,到这里你已经清楚了,代码复用并不是使用继承的好场景。所以,要写继承的代码时,先问自己,这是接口继承,还是实现继承?如果是实现继承,那是不是可以写成组合?
面向组合编程
- 之所以可以用组合的方式实现,本质的原因是,获取产品信息和生成报表服务本来就是两件事。还记得我们在第 3 讲里讲过的“分离关注点”吗?如果你能看出它们是两件事,就不会把它们放到一起了。
- 我还讲过,分解是设计的第一步,而且分解的粒度越小越好。当你可以分解出来多个关注点,每一个关注点就应该是一个独立的模块。最终的类是由这些一个一个的小模块组合而成,这种编程的方式就是面向组合编程。它相当于换了一个视角:类是由多个小模块组合而成。
- 还以前面的报表服务为例,如果使用 Java,按照面向组合的思路写出来,大概是下面这样的。其中,为了增加复杂度,我增加了一个报表生成器(ReportGenerator),在获取产品信息之后,还要生成报表:
- class ReportService {
- private ProductFetcher fetcher;
- private ReportGenerator generator;
- public void report() {
- List<Product> product = fetcher.getProducts(...);
- generator.generate(product);
- }
- 请注意,我在前面的表述中,故意用了模块这个词,而不是类。因为 ProductFetcher 和 ReportGenerator 只是因为我们用的是 Java,才写成了类;如果用 Ruby,它们的表现形式就会是一个 module;而在 Scala 里,就会成为一个 trait。我们再用 Ruby 示意一下:
- class ReportService
- include ProductFetcher
- include ReportGenerator
- def report
- products = getProducts(...)
- generateReport(products)
- end
- end
- 而使用 C++ 的话,表现形式则会是私有继承:
- class ReportService: private ProductFetcher, private ReportGenerator {
- ...
- C++ 本身支持宏定义,所以,我们可以自定义一些宏,将这些不同的概念区分开来:
- 上面的类定义就可以变成更有表达性的写法:
- MODULE(ProductFetcher) {
- ...
- MODULE(ReportGenerator) {
- ...
- class ReportService:
- INCLUDE(ProductFetcher),
- INCLUDE(ReportGenerator) {
- ...
- 我有一个 C++ 的高手朋友,把这种做法称之为“小类大对象”,这里面的小类就是一个一个的模块,而最终的大对象是最终组合出来的类生成的对象。
- 关于面向对象,有一点我们还没有说,就是面向对象面向的是“对象”,不是类。很多程序员习惯把对象理解成类的附属品,但在 Alan Kay 的理解中,对象本身就是一个独立的个体。所以,有些程序设计语言可以直接支持在对象上进行操作。
- 还是前面的例子,我想给报表服务增加一个接口,对产品信息做一下处理。用 Ruby 写出来会是这样:
- module ProductEnhancer
- def enhance
- end
- end
- service = ReportService.new
- service.extend(ProductEnhancer)
- service.enhance
- 这样的处理只会影响这里的一个对象,而同样是这个 ReportService 的其他实例,则完全不受影响。这样做的好处是,我们不必写那么多类,而是根据需要在程序运行时组合出不同的对象。
- 在这里,相信你再一次意识到了要学习多种程序设计语言的重要性。Java 只有类这种组织方式,所以,很多有差异的概念只能用类这一个概念表示出来,思维就会受到限制,而不同的语言则提供了不同的表现形式,让概念更加清晰。
- 前面只是讲了面向组合编程在思考方式的转变,下面我们再来看设计上的差异。举个例子,我们有个字体类(Font),现在的需求是,字体能够加粗(Bold)、能够有下划线(Underline)、还要支持斜体(Italic),而且这些能力之间是任意组合的。
- 如果采用继承的方式,那就要有 8 个类:
- 
- 而采用组合的方式,我们的字体类(Font)只要有三个独立的维度,也就是是否加粗(Bold)、是否有下划线(Underline)、是否是斜体(Italic)。这还不是终局,如果再来一种其他的要求,由 3 种要求变成 4 种,采用继承的方式,类的数量就会膨胀到 16 个类,而组合的方式只需要再增加一个维度就好。我们把一个 M\*N 的问题,通过设计转变成了 M+N 的问题,复杂度的差别一望便知。
- 虽然我们一直在说,Java 在面向组合编程方面能力比较弱,但 Java 社区也在尝试不同的方式。早期的尝试有Qi4j,后来 Java 8 加入了 default method,在一定程度上也可以支持面向组合的编程。这里我们只是讲了面向对象社区在组合方面的探索,后面讲函数式编程时,还会讲到函数式编程在这方面的探索。
总结时刻
- 今天,我们学习了面向对象的第二个特点:继承。继承分为两种,实现继承和接口继承。实现继承是站在子类的视角看问题,接口继承则是站在父类的视角。
- 很多程序员把实现继承当作了一种代码复用的方式,但实际上,实现继承并不是一个好的代码复用的方式,之所以这种方式很常见,很大程度上是受了语言的局限。
- Ruby 的 mixin 机制,Scala 提供的 trait 以及 C++ 提供的私有继承都是代码复用的方式。即便只使用 Java,也可以通过组合而非继承的方式进行代码复用。
- 今天我们还讲到这些复用方式背后的编程思想:面向组合编程。它给我们提供了一个不同的视角,但支撑面向组合编程的是分离关注点。将不同的关注点分离出来,每一个关注点成为一个模块,在需要的时候组装起来。面向组合编程,在设计本身上有很多优秀的地方,可以降低程序的复杂度,更是思维上的转变。
- 现在你已经知道了,在继承树上从下往上看,并不是一个好的思考方式,那从上往下看呢?下一讲,我们就来讲讲继承的另外一个方向,接口继承,也就是面向对象的第三个特点:多态。
- 如果今天的内容你只能记住一件事,那请记住:组合优于继承。
- 
思考题
- 最后,我想请你去了解一下一种叫DCI (Data,Context 和 Interaction)
- 的编程思想,结合今天的课程,分享一下你对 DCI 的理解。欢迎在留言区分享你的想法。
- 感谢阅读,如果你觉得这一讲的内容对你有帮助的话,也欢迎把它分享给你的朋友。
16 | 面向对象之多态(Polymorphism):为什么“稀疏平常”的多态,是软件设计的大杀器?
前面两讲,我们讲了面向对象的两个特点:封装和继承,但真正让面向对象华丽蜕变的是它的第三个特点:多态。
有一次,我在一个 C++ 的开发团队里做了一个小调查。问题很简单:你用过 virtual 吗?下面坐着几十个 C++ 程序员,只有寥寥数人举起了手。
在 C++ 里,virtual 表示这个函数是在父类中声明的,然后在子类中改写(Override)过 。或许你已经发现了,这不就是多态吗?没错,这就是多态。这个调查说明了一件事,很多程序员虽然在用支持面向对象的程序设计语言,但根本没有用过多态。只使用封装和继承的编程方式,我们称之为基于对象(Object Based)编程,而只有把多态加进来,才能称之为面向对象(Object Oriented)编程。也就是说,多态是一个分水岭,将基于对象与面向对象区分开来,可以说,没写过多态的代码,就是没写过面向对象的代码 。对于面向对象而言,多态至关重要,正是因为多态的存在,软件设计才有了更大的弹性,能够更好地适应未来的变化。我们说,软件设计是一门关注长期变化的学问,只有当你开始理解了多态,你才真正踏入应对长期变化的大门。这一讲,我们就谈谈多态。
理解多态
- 多态(Polymorphism),顾名思义,一个接口,多种形态。同样是一个绘图(draw)的方法,如果以正方形调用,则绘制出一个正方形;如果以圆形调用,则画出的是圆形:
interface Shape {
void draw();
class Square implements Shape {
void draw() {
}
class Circle implements Shape {
void draw() {
}
- 上一讲,我们说过,继承有两种,实现继承和接口继承。其中,实现继承尽可能用组合的方式替代继承。而接口继承,主要是给多态用的。
- 这里面的重点在于,这个继承体系的使用者,主要考虑的是父类,而非子类。就像下面这段代码里,我们不必考虑具体的形状是什么,只要调用它的绘图方法即可。
Shape shape = new Squre();
shape.draw();
- 这种做法的好处就在于,一旦有了新的变化,比如,需要将正方形替换成圆形,除了变量初始化,其他的代码并不需要修改。不过,这是任何一本面向对象编程的教科书上都会讲的内容。
- 那么,问题来了。==既然多态这么好,为什么很多程序员不能在自己的代码中很好地运用多态呢?因为多态需要构建出一个抽象==。
- 构建抽象,需要找出不同事物的共同点,而这是最有挑战的部分。而遮住程序员们双眼的,往往就是他们眼里的不同之处。在他们眼中,鸡就是鸡,鸭就是鸭。
- 寻找共同点这件事,地基还是在分离关注点上。只有你能看出来,鸡和鸭都有羽毛,都养在家里,你才有机会识别出一个叫做“家禽”的概念。这里,我们又一次强调了分离关注点的重要性。
- 我们构建出来的抽象会以接口的方式体现出来,强调一点,这里的接口不一定是一个语法,而是一个类型的约束。所以,在这个关于多态的讨论中,接口、抽象类、父类等几个概念都是等价的,为了叙述方便,我这里统一采用接口的说法。
- 在构建抽象上,接口扮演着重要的角色。首先,接口将变的部分和不变的部分隔离开来。不变的部分就是接口的约定,而变的部分就是子类各自的实现。
- 在软件开发中,对系统影响最大的就是变化。有时候需求一来,你的代码就要跟着改,一个可能的原因就是各种代码混在了一起。比如,一个通信协议的调整需要你改业务逻辑,这明显就是不合理的。对程序员来说,识别出变与不变,是一种很重要的能力。
- 其次,接口是一个边界。无论是什么样的系统,清晰界定不同模块的职责是很关键的,而模块之间彼此通信最重要的就是通信协议。这种通信协议对应到代码层面上,就是接口。
- 很多程序员在接口中添加方法显得很随意,因为在他们心目中,并不存在实现者和使用者之间的角色差异。这也就造成了边界意识的欠缺,没有一个清晰的边界,其结果就是模块定义的随意,彼此之间互相影响也就在所难免。后面谈到 Liskov 替换法则的时候,我们还会再谈到这一点。
- 所以,要想理解多态,首先要理解接口的价值,而理解接口,最关键的就是在于谨慎地选择接口中的方法。
- 至此,你已经对多态和接口有了一个基本的认识。你就能很好地理解一个编程原则了:面向接口编程。面向接口编程的价值就根植于多态,也正是因为有了多态,一些设计原则,比如,开闭原则、接口隔离原则才得以成立,相应地,设计模式才有了立足之本。
- 这些原则你可能都听说过,但在编码的细节上,你可能会有一些忽略的细节,比如,下面这段代码是很多人经常写的:
ArrayList<> list = new ArrayList<String>();
- 这么简单的代码也有问题,是的,因为它没有面向接口编程,一个更好的写法应该是这样:
List<> list = new ArrayList<String\>();
- 二者之间的差别就在于变量的类型,是面向一个接口,还是面向一个具体的实现类。
- 相对于封装和继承而言,多态对程序员的要求更高,需要你有长远的眼光,看到未来的变化,而理解好多态,也是程序员进阶的必经之路。
实现多态
- 还记得我们在编程范式那一讲留下的一个问题吗?面向对象编程,会限制使用函数指针,它是对程序控制权的间接转移施加了约束。理解这一点,就要理解多态是怎么实现的。
- 讲多范式编程时,我举了 Linux 文件系统的例子,它是用 C 实现了面向对象编程,而它的做法就是用了函数指针。再来回顾一下:
struct file_operations {
loff_t (*llseek) (struct file *, loff_t, int);
ssize_t (*read) (struct file *, char __user *, size_t, loff_t *);
ssize_t (*write) (struct file *, const char __user *, size_t, loff_t *);
int (*open) (struct inode *, struct file *);
int (*flush) (struct file *, fl_owner_t id);
int (*release) (struct inode *, struct file *);
...
- 假设你写一个 HelloFS,那你可以这样给它赋值:
const struct file_operations hellofs_file_operations = {
.read = hellofs_read,
.write = hellofs_write,
- 只要给这个结构体赋上不同的值,就可以实现不同的文件系统。但是,这种做法有一个非常不安全的地方。既然是一个结构体的字段,那我就有可能改写了它,像下面这样:
void silly_operation(struct file_operations* operations) {
operations.read = sillyfs_read;
- 如此一来,本来应该在 hellofs\_read 运行的代码,就跑到了 sillyfs\_read 里,程序很容易就崩溃了。==对于 C 这种非常灵活的语言来说,你根本禁止不了这种操作,只能靠人为的规定和代码检查==。
- ==到了面向对象程序设计语言这里,这种做法由一种编程结构变成了一种语法。给函数指针赋值的操作下沉到了运行时去实现==。如果你了解运行时的实现,它就是一个查表的过程,如下图所示:
- 
- 一个类在编译时,会给其中的函数在虚拟函数表中找到一个位置,把函数指针地址写进去,不同的子类对应不同的虚拟表。当我们用接口去调用对应的函数时,实际上完成的就是在对应的虚拟函数表的一个偏移,不管现在面对的是哪个子类,都可以找到相应的实现函数。
- 还记得我在开头提的那个问题吗?问 C++ 程序员是否用过 virtual。==在 C++ 这种比较注重运行时消耗的语言中,只有 virtual 的函数会出现在虚拟函数表里,而普通函数就是直接的函数调用,以此减少消耗。对于 Java 程序员而言,你可以通过给无需改写的方法添加 final 帮助运行时做优化==。
- 当多态成了一种语法,函数指针的使用就得到了限制,犯错误的几率就大大降低了,程序行为的可预期性就大大提高了。
没有继承的多态
- 回到 Alan Kay 关于面向对象的思考中,他考虑过封装,考虑过多态。至于继承,却不是一个必然的选项。只要能够遵循相同的接口,就可以表现出来多态,所以,多态并不一定要依赖于继承。
- 比如,在动态语言中,有一个常见的说法,叫 ==Duck Typing,就是说,如果走起来像鸭子,叫起来像鸭子,那它就是鸭子==。两个类可以不在同一个继承体系之下,但是,只要有同样的方法接口,就是一种多态。
- 像下面这段代码,Duck 和 FakeDuck 并不在一棵继承树上,但 make\_quack 调用的时候,它们俩都可以传进去。
class Duck
def quack
end
end
class FakeDuck
def quack
end
end
def make_quack(quackable)
quackable.quack
end
make_quack(Duck.new)
make_quack(FakeDuck.new)
- 我们都知道,很多软件都有插件能力,而插件结构本身就是一种多态的表现。比如,著名的开源图形处理软件GIMP,它自身是用 C 开发的,为它编写插件就需要按照它规定的结构去编写代码:
struct GimpPlugInInfo{
/* GIMP 应用初始启动时调用 */
GimpInitProc init_proc;
/* GIMP 应用退出时调用 */
GimpQuitProc quit_proc;
/* GIMP 查询插件能力时调用 */
GimpQueryProc query_proc;
/*插件安装之后,开始运行时调用 */
GimpRunProc run_proc;
}
- 我们所需做的就是按照这个结构声明出 PLUG\_IN\_INFO,这是隐藏的名字,将插件的能力注册给 GIMP 这个应用:
GimpPlugInInfo PLUG_IN_INFO = {
init,
quit,
query,
run
};
- 你看,这里用到的是 C 语言,一种连面向对象都不支持的语言,但它依然能够很好地表现出多态。
- 现在你应该理解了,==多态依赖于继承,这只是某些程序设计语言自身的特点。你也看出来了,在面向对象本身的体系之中,封装和多态才是重中之重,而继承则处于一个很尴尬的位置==。
- 我们花了三讲的篇幅讲了面向对象编程的特点,在这三讲中,我们不仅仅以 Java 为基础讲了传统的面向对象实现的一些方法,也讲到了不同语言在解决同样问题上的不同做法。正如我们在讲程序设计语言时所说,一定要跳出单一语言的局限,这样,才能对各种编程思想有更本质的认识。
- 在这里,你也看到了面向对象编程的三个特点也有不同的地位:
- 封装是面向对象的根基,软件就是靠各种封装好的对象逐步组合出来的;
- 继承给了继承体系内的所有对象一个约束,让它们有了统一的行为;
- 多态让整个体系能够更好地应对未来的变化。
- 后面我们还会讲到面向对象的设计原则,而这些原则的出发点就是面向对象的这些特点,所以,理解面向对象的这些特点,是我们后面把设计做好的基础。
- 
17 | 函数式编程:不用函数式编程语言,怎么写函数式的程序?
你可能知道,Java 和 C++ 已经引入了 Lambda,目的就是为了支持函数式编程。因为,函数式编程里有很多优秀的元素,比如,组合式编程、不变性等等,都是我们值得在日常设计中借鉴的。即便我们使用的是面向对象编程语言,也可以将这些函数式编程的做法运用到日常工作中,这已经成为大势所趋。
但是,很多人学习函数式编程,刚刚知道了概念,就碰上了函数式编程的起源,遇到许多数学概念,然后,就放弃了。为什么学习函数式编程这么困难呢?主要是因为它有一些不同的思维逻辑,同时人们也缺少一个更好的入门方式。
所以,在这一讲中,我打算站在一个更实用的角度,帮你做一个函数式编程的入门。等你有了基础之后,后面两讲,我们再来讨论函数式编程中优秀的设计理念。
好,我们开始吧!
不断增加的需求
- 我们从一个熟悉的场景出发。假设我们有一组学生,其类定义如下:
class Student {
private long id;
private String name;
private long sno;
private long age;
}
class Students {
private List<Student> students
}
- 如果我们需要按照姓名找出其中一个,代码可能会这么写:
Student findByName(final String name) {
for (Student student : students) {
if (name.equals(student.getName())) {
return student;
}
}
return null;
}
- 如果我们需要按照姓名找出其中一个,代码可能会这么写:
Student findByName(final String name) {
for (Student student : students) {
if (name.equals(student.getName())) {
return student;
}
}
return null;
}
- 如果我们需要按照姓名找出其中一个,代码可能会这么写:
Student findByName(final String name) {
for (Student student : students) {
if (name.equals(student.getName())) {
return student;
}
}
return null;
}
- 这时候,新需求来了,我们准备按照学号来找人,代码也许就会这么写:
Student findBySno(final long sno) {
for (Student student : students) {
if (sno == student.getSno()) {
return student;
}
}
return null;
}
``` 又一个新需求来了,我们这次需要按照 ID 去找人,代码可以如法炮制:
Student findById(final long id) {
for (Student student : students) {
if (id == student.getId()) {
return student;
}
}
return null;
}
- 看完这三段代码,你发现问题了吗?这三段代码,除了查询的条件不一样,剩下的结构几乎一模一样,这就是一种重复。
那么,我们要怎么消除这个重复呢?我们可以引入查询条件这个概念,这里只需要返回一个真假值,我们可以这样定义:
interface Predicate<T\> {
boolean test(T t);
}
有了查询条件,我们可以改造一下查询方法,把条件作为参数传进去:
Student find(final Predicate<Student> predicate) {
for (Student student : students) {
if (predicate.test(student)) {
return student;
}
}
return null;
}
于是,按名字查找就会变成下面这个样子(其他两个类似,就不写了)。为了帮助你更好地理解,我没有采用 Java 8 的 Lambda 写法,而用了你最熟悉的对象:
Student findByName(final String name) {
return find(new Predicate<Student>() {
@Override
public boolean test(final Student student) {
return name.equals(student.getName();
}
});
}
这样是很好,但你会发现,每次有一个新的查询,你就要做一层这个封装。为了省去这层封装,我们可以把查询条件做成一个方法:
static Predicate<Student> byName(final String name) {
return new Predicate<Student>() {
@Override
public boolean test(final Student student) {
return name.equals(student.getName();
}
}
}
- 其他几个字段也可以做类似的封装,这样一来,要查询什么就由使用方自己决定了:
find(byName(name));
find(bySno(sno));
find(byId(id));
现在我们想用名字和学号同时查询,该怎么办呢?你是不是打算写一个 byNameAndSno 的方法呢?且慢,这样一来,岂不是每种组合你都要写一个?那还受得了吗。我们完全可以用已有的两个方法组合出一个新查询来,像这样:
find(and(byName(name), bySno(sno)));
这里面多出一个 and 方法,它要怎么实现呢?其实也不难,按照正常的 and 逻辑写一个就好,像下面这样:
static <T> Predicate<T> and(final Predicate<T>... predicates) {
return new Predicate<T>() {
@Override
public boolean test(final T t) {
for (Predicate<T> predicate : predicates) {
if (!predicate.test(t)) {
return false;
}
}
return true;
}
};
}
类似地,你还可以写出 or 和 not 的逻辑,这样,使用方能够使用的查询条件一下子就多了起来,他完全可以按照自己的需要任意组合。
- 这时候,又来了一个新需求,想找出所有指定年龄的人。写一个 byAge 现在已经很简单了。那找到所有人该怎么写呢?有了前面的基础也不难。
Student findAll(final Predicate<Student> predicate) {
List<Student> foundStudents = new ArrayList<Student>();
for (Student student : students) {
if (predicate.test(student)) {
foundStudents.add(student);
}
}
return new Students(foundStudents);
}
如此一来,要做什么动作(查询一个、查询所有等)和用什么条件(名字、学号、ID 和年龄等)就成了两个维度,使用方可以按照自己的需要任意组合。
直到现在,我们所用的代码都是常规的 Java 代码,却产生了神奇的效应。这段代码的作者只提供了各种基本元素(动作和条件),而这段代码的用户通过组合这些基本的元素完成真正的需求。这种做法完全不同于常规的面向对象的做法,其背后的思想就源自函数式编程。
- ==在上面这个例子里面,让代码产生质变的地方就在于 Predicate 的引入,而它实际上就是一个函数==。
- 这是一个简单的例子,但是我们可以发现,按照“消除重复”这样一个简单的编写代码逻辑,我们不断地调整代码,就是可以写出这种函数式风格的代码。在写代码这件事上,我们常常会有一种殊途同归的感觉。
- 现在,你已经对函数式编程应该有了一个初步的印象,接下来,我们看看函数式编程到底是什么。
## 函数式编程初步
- 函数式编程是一种编程范式,它提供给我们的编程元素就是函数。只不过,这个函数是来源于数学的函数,你可以回想一下,高中数学学到的那个 f(x)。同我们习惯的函数相比,它要规避状态和副作用,换言之,同样的输入一定会给出同样的输出。
- 之所以说函数式编程的函数来自数学,因为它的起源是数学家 Alonzo Church 发明的 Lambda 演算(Lambda calculus,也写作 λ-calculus)。所以,Lambda 这个词在函数式编程中经常出现,==你可以简单地把它理解成匿名函数==。
- 我们这里不关心 Lambda 演算的数学逻辑,你只要知道,Lambda 演算和图灵机是等价的,都是那个年代对“计算”这件事探索的结果。
- 我们现在接触的大多数程序设计语言都是从图灵机的模型出发的,但==既然二者是等价的,就有人选择从 Lambda 演算出发。比如早期的函数式编程语言 LISP,它在 20 世纪 50 年代就诞生了,是最早期的几门程序设计语言之一。它的影响却是极其深远的,后来的函数式编程语言可以说都直接或间接受着它的影响==。
- 虽然说函数式编程语言早早地就出现了,但函数式编程这个概念却是 John Backus 在其1977 年图灵奖获奖的演讲上提出来。有趣的是,John Backus 获奖的理由是他在 Fortran 语言上的贡献,而这门语言和函数式编程刚好是两个不同“计算”模型的极端。
了解了函数式编程产生的背景之后,我们就可以正式打开函数式编程的大门了。
- 函数式编程第一个需要了解的概念就是函数。在函数式编程中,函数是一等公民(first-class citizen)。
- ==一等公民是什么意思呢?==
- 它可以按需创建;
- 它可以存储在数据结构中;
- 它可以当作实参传给另一个函数;
- 它可以当作另一个函数的返回值。
- 对象,是面向对象程序设计语言的一等公民,它就满足所有上面的这些条件。在函数式编程语言里,函数就是一等公民。函数式编程语言有很多,经典的有 LISP、Haskell、Scheme 等,后来也出现了一批与新平台结合紧密的函数式编程语言,比如:Clojure、F\#、Scala 等。
- 很多语言虽然不把自己归入函数式编程语言,但它们也提供了函数式编程的支持,比如支持了 Lambda 的,这类的语言像 Ruby、JavaScript 等。
- 如果你的语言没有这种一等公民的函数支持,完全可以用某种方式模拟出来。在前面的例子里,我们就用对象模拟出了一个函数,也就是 Predicate。==在旧版本的 C++ 中,也可以用 functor(函数对象)当作一等公民的函数。==在这两个例子中,既然函数是用对象模拟出来的,自然就符合一等公民的定义,可以方便将其传来传去。
- 在开头,我提到过,随着函数式编程这几年蓬勃的发展,越来越多的“老”程序设计语言已经在新的版本中加入了对函数式编程的支持。所以,如果你用的是新版本,可以不必像我写得那么复杂。
- 比如,在 Java 里,Predicate 本身就是 JDK 自带的,and 方法也不用自己写,加上有 Lambda 语法简化代码的编写,代码可以写成下面这样,省去了构建一个匿名内部类的繁琐:
static Predicate<Student> byName(String name) {
return student -> student.getName().equals(name);
}
find(byName(name).and(bySno(sno)));
- 如果按照对象的理解方式,Predicate 是一个对象接口,但它可以接受一个 Lambda 为其赋值。有了前面的基础,你可以把它理解成一个简化版的匿名内部类。==其实,这里面主要工作都在编译器上,它帮助我们做了类型推演(Type Inference)。==
- 在 Java 里,可以表示一个函数的接口还有几个,比如,Function(一个参数一个返回值)、Supplier(没有参数只有返回值),以及一大堆形式稍有不同的变体。
- 这些“函数”的概念为我们提供了一些基础的构造块,从前面的例子,你可以看出,函数式编程一个有趣的地方就在于这些构造块可以组合起来,这一点和面向对象是类似的,都是由基础的构造块逐步组合出来的。
- 我们讲模型也好,面向对象也罢,对于这种用小组件逐步叠加构建世界的思路已经很熟悉了,在函数式编程里,我们又一次领略到同样的风采,而这一切的出发点,就是“函数”。
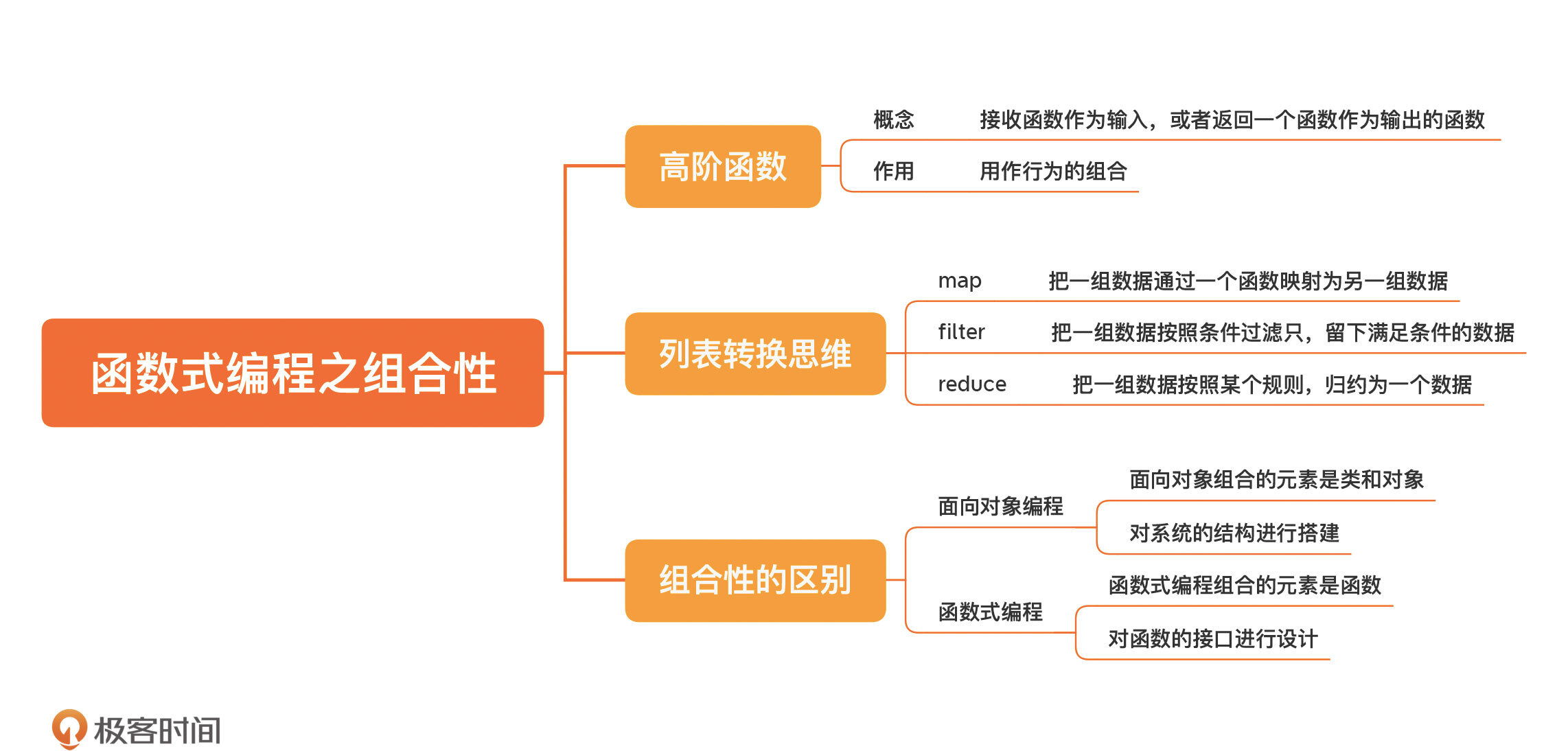
- 18 | 函数式编程之组合性:函数式编程为什么如此吸引人?
- 从上一讲开始,我们开启了函数式编程之旅,相信你已经对函数式编程有了一个初步的认识。函数式编程是一种以函数为编程元素的编程范式。但是,如果只有函数这一样东西,即使是说出花来,也没有什么特别的地方。
- 之前我讲过,==GC 来自于函数式编程,Lambda 也来自于函数式编程。此外,在 Java 8 增加的对函数式编程的处理中,流(Stream)的概念也从函数式编程中来,Optional 也和函数式编程中的一些概念有着紧密的联系。由此可见,函数式编程给我们提供了许多优秀的内容==。
- 接下来,我们来讲讲函数式编程在设计上对我们帮助最大的两个特性:==组合性和不变性。==
- 首先,我们来讨论一下组合性,看看函数式编程为什么能够如此吸引人。
## 组合行为的高阶函数
- 在函数式编程中,==有一类比较特殊的函数,它们可以接收函数作为输入,或者返回一个函数作为输出。这种函数叫做高阶函数(High-order function)。==
- 听上去稍微有点复杂,如果我们回想一下高中数学里有一个复合函数的概念,也就是 f(g(x)) ,把一个函数和另一个函数组合起来,这么一类比,是不是就好接受一点了。
- 那么,高阶函数有什么用呢?它的一个重要作用在于,我们可以用它去做行为的组合。我们再来回顾一下上一讲写过的一段代码:
- `find(byName(name).and(bySno(sno)));`
- 在这里面,find 的方法就扮演了一个高阶函数的角色。它接收了一个函数作为参数,由此,一些处理逻辑就可以外置出去。这段代码的使用者,就可以按照自己的需要任意组合。
- 你可能注意到了,这里的 find 方法只是一个普通的 Java 函数。是这样的,==如果不需要把这个函数传来传去,普通的 Java 函数也可以扮演高阶函数的角色==。
- 可以这么说,==高阶函数的出现,让程序的编写方式出现了质变。按照传统的方式,程序库的提供者要提供一个又一个的完整功能,就像 findByNameAndBySno 这样,但按照函数式编程的理念,提供者提供的就变成了一个又一个的构造块,像 find、byName、bySno 这样。然后,使用者可以根据自己的需要进行组合,非常灵活,甚至可以创造出我们未曾想过的组合方式==。
- 这就是典型的函数式编程风格。模型提供者提供出来的是一个又一个的构造块,以及它们的组合方式。由使用者根据自己需要将这些构造块组合起来,提供出新的模型,供其他开发者使用。就这样,模型之间一层又一层地逐步叠加,最终构建起我们的整个应用。
- 前面我们讲过,一个好模型的设计就是逐层叠加。函数式编程的组合性,就是一种好的设计方式。
- 但是,能把模型拆解成多个可以组合的构造块,这个过程非常考验人的洞察力,也是“分离关注点”的能力,但是这个过程可以让人得到一种智力上的愉悦。为什么函数式编程一直处于整个 IT 行业的角落里,还能吸引一大批优秀的开发者前赴后继地投入其中呢?这种智力上的愉悦就是一个重要的原因。
- 没错,是构建了一门语言。有了语言,你就可以去完成任何你想做的事了。这篇文章非常好地体现了函数式编程社区这种逐步叠加构建模型的思想。有兴趣的话,你可以去读一下。
- 当我们把模型拆解成小的构造块,如果构造块足够小,我们自然就会发现一些通用的构造块。
## 列表转换思维
- 我们说过,早期的函数式编程探索是从 LISP 语言开始的。LISP 这个名字源自“List Processing”,这个名字指明了这个语言中的一个核心概念:List,也就是列表。程序员对 List 并不陌生,这是一种最为常用的数据结构,现在的程序语言几乎都提供了各自 List 的实现。
- LISP 的一个洞见就是,大部分操作最后都可以归结成列表转换,也就是说,数据经过一系列的列表转换会得到一个结果,如下图所示:
- 
- 想要理解这一系列的转换,就要先对每个基础的转换有所了解。==最基础的列表转换有三种典型模式,分别是 map、filter 和 reduce。如果我们能够正确理解它们,基本上就可以把 for 循环抛之脑后了。做过大数据相关工作的同学一定听说过一个概念:MapReduce,这是最早的一个大数据处理框架,这里的 map 和 reduce 就是源自函数式编程里列表转换的模式==。
- 接下来,我们就来一个一个地看看它们分别是什么。
- 首先是 map。map 就是把一组数据通过一个函数映射为另一组数据。
- 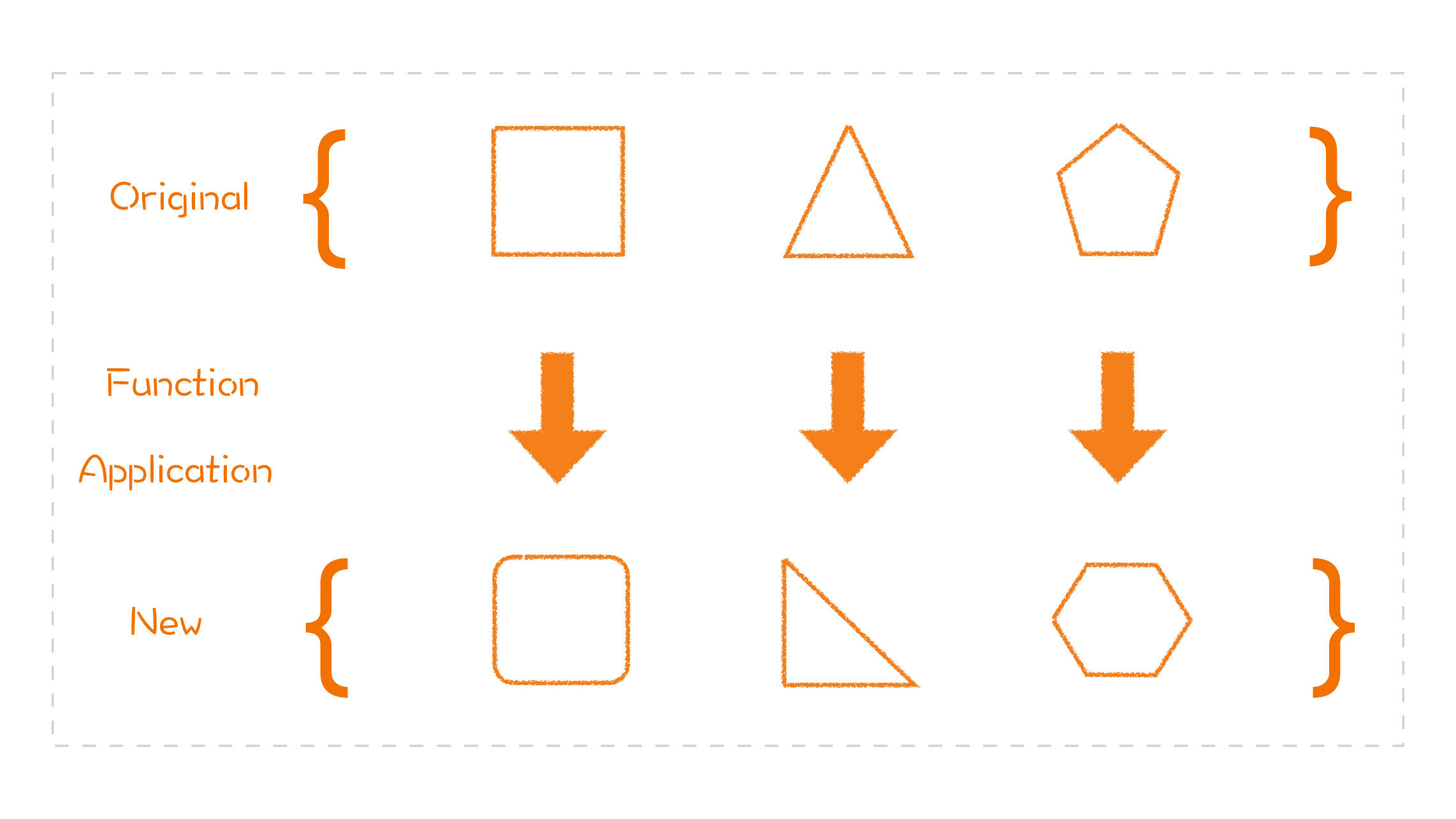
- 比如,我有一组数\[1、2、3、4\],然后做了一个 map 操作,这里用作映射的函数是乘以 2,也就是说,这组数里面的每个元素都乘以 2,这样,我就得到了一组新的数\[2、4、6、8\]。
- 再来看 filter。filter 是把一组数据按照某个条件进行过滤,只有满足条件的数据才会留下。
- 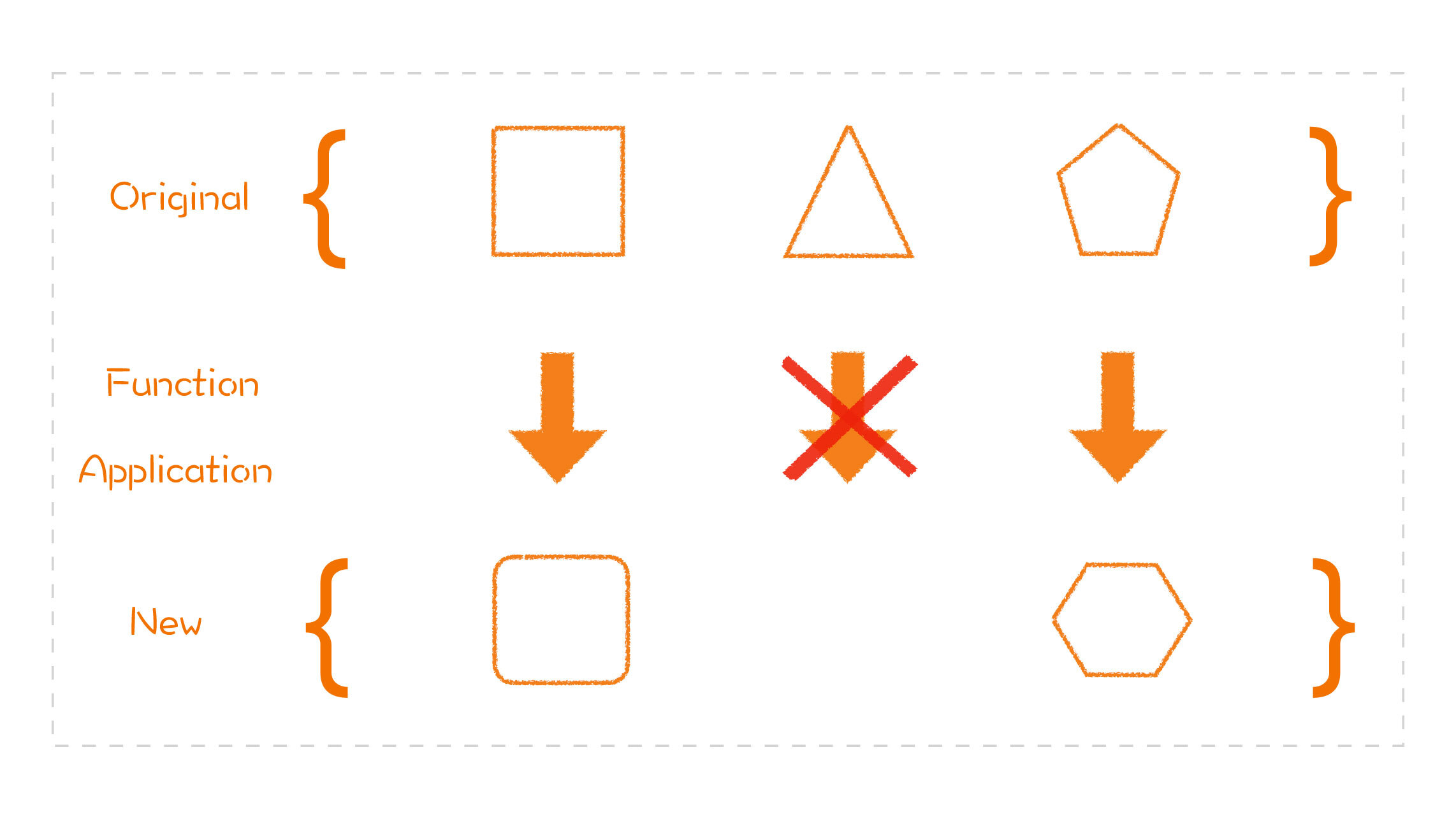
- 同样\[1、2、3、4\]为例,我们做一个 filter 操作,过滤的函数是大于 2,也就是说,只有大于 2 的数才会留下,得到的结果就是\[3、4\]。
- 最后是 reduce。reduce 就是把一组数据按照某个规则,归约为一个数据。
- 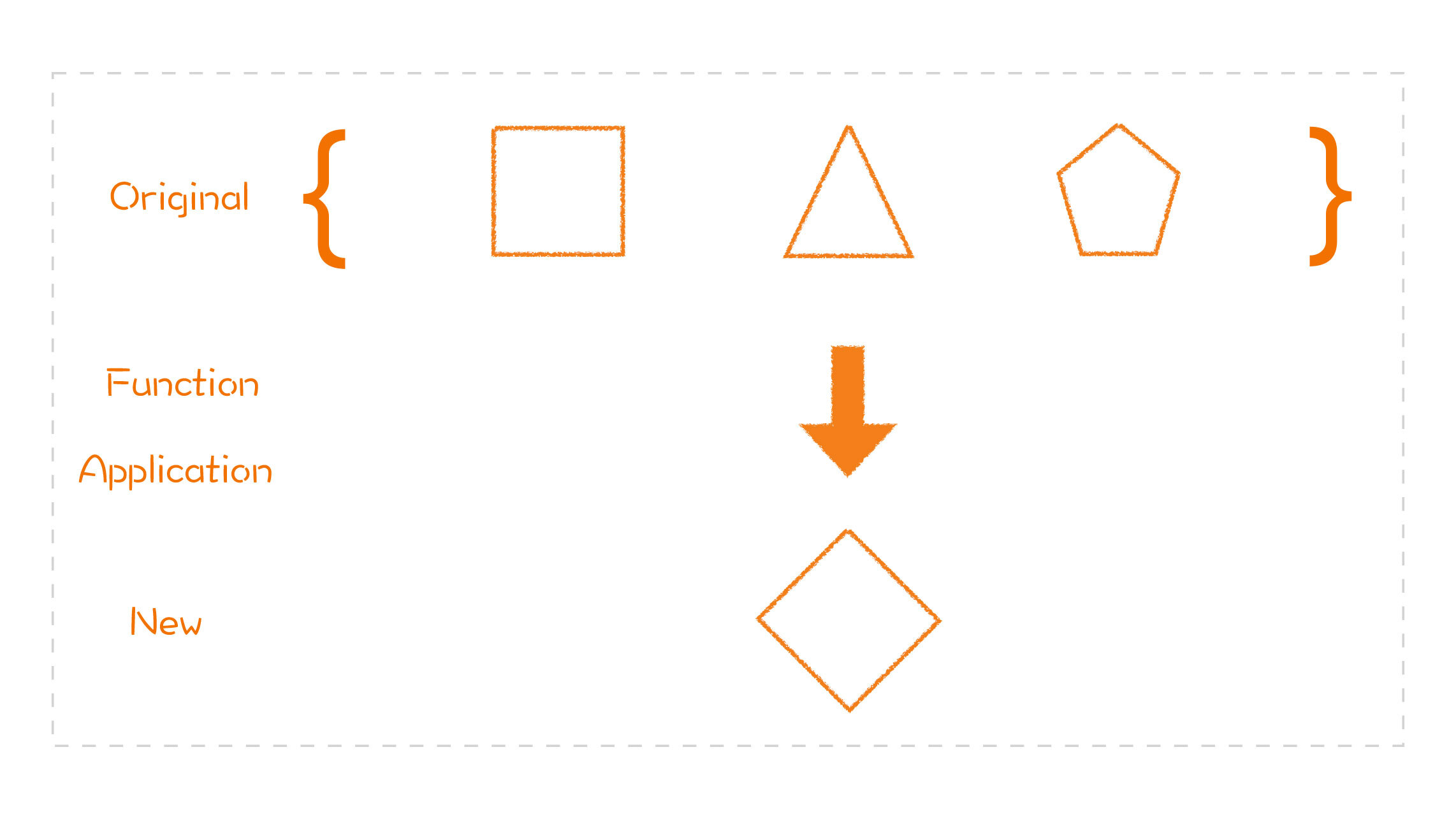
- 还是\[1、2、3、4\],如果我们做一个 reduce 操作,其归约函数是一个加法操作,也就是这组数里面的每个元素相加,最终会得到一个结果,也就是 1+2+3+4=10。
- 好,有了基础之后,我们就可以利用这些最基础的转换模式去尝试解决问题了。
- 比如,上一讲我们讲了一个学生的例子,现在,我们想知道这些学生里男生的总数。我们可以给 Student 类增加一个性别的字段:
class Student {
...
private Gender gender;
- 要想知道男生的总数,传统做法应该是这么做:
long countMale() {
long count = 0;
for (Student student : students) {
if (Gender.MALE == student.getGender())) {
count++;
}
}
return count;
- 按照列表转换的思维来做的话,我们该怎么做呢?首先,要把这个过程做一个分解:
- 这三步刚好对应着 map、filter 和 reduce:
- 取出性别字段,对应着 map,其映射函数是取出学生的性别字段;
- 判别性别是否为男性,对应 filter,其过滤函数是,性别为男性;
- 计数加 1,对应着 reduce,其归约函数是,加 1。
- 有了这个分解的结果,我们再把它映射到代码上。Java 8 对于函数式编程的支持,除了 Lambda 之外,它也增加了对列表转换的支持。为了兼容原有的 API,它提供了一个新的接口:Stream,你可以把它理解成 List 的另一种表现形式。如果把上面的步骤用 Java 8 的 Stream 方式写出来,代码应该是这样的:
long countMale() {
return students.stream()
.map(student -> student.getGender())
.filter(gender -> gender == Gender.MALE)
.map(gender -> 1L)
.reduce(0L, (sum, element) -> sum + element);
- 这基本和上面操作步骤是一一对应的,只是多了一步将性别转换成 1,便于后面的计算。
- map、filter 和 reduce 只是最基础的三个操作,列表转换可以提供的操作远远比这个要多。不过,你可以这么理解,大多数都是在这三个基础上进行了封装,提供一种快捷方式。比如,上面代码的最后两步 map 和 reduce,在 Java 8 的 Stream 接口提供了一个 count 方式,可以写成方法:
long countMale() {
return students.stream()
.map(Student:getGender)
.filter(byGender(Gender.MALE))
.count();
static Predicate<Gender> byGender(final Gender target) {
return gender -> gender == target;
- 一方面,我用了方法引用(Student:getGender),这是 Java 提供的简化代码编写的一种方式。另一方面,我还把按照性别比较提取了出来,如此一来,代码的可读性就提升了,你基本上可以把它同前面写的操作步骤完全对应起来了。
- ==同样是一组数据的处理,我更鼓励使用函数式的列表转换,而不是传统的 for 循环。一方面因为它是一种更有表达性的写法,从前面的代码就可以看到,它几乎和我们想做的事是一一对应的。另一方面,这里面提取出来比较性别的方法,它就是一个可以用作组合的基础接口,可以在多种场合复用==。
- 很多 Java 程序员适应不了这种写法,一个重要的原因在于,他们缺少对于列表转换的理解。缺少了一个重要的中间环节,必然会出现不适。
- 你回想一下,我们说过结构化编程给我们提供了一些基础的控制结构,那其实也是一层封装,只不过,我们在编程之初就熟悉了 if、for 之类的写法。如果你同样熟悉函数式编程的基础设施,这些代码理解起来同那些控制结构没有什么本质区别,而且这些基础设施的抽象级别要比那些控制结构更高,提供了更好的表达性。
- 我们之前在讲 DSL 的时候就谈到过代码的表达性,其中一个重要的观点就是,有一个描述了做什么的接口之后,具体怎么做就可以在背后不断地进行优化。比如,如果一个列表的数据特别多,我们可以考虑采用并发的方式进行处理,而这种优化在使用端完全可以做到不可见。MapReduce 甚至将运算分散到不同的机器上执行,其背后的逻辑是一致的。
## 面向对象与函数式编程的组合
- 至此,我们已经学习了函数式编程的组合。你可能会有一个疑问,我们之前在讲面向对象的时候,也谈到了组合,这里讲函数式编程,又谈到了组合。这两种组合之间是什么关系呢?其实,对比一下代码,你就不难发现了,==面向对象组合的元素是类和对象,而函数式编程组合的是函数==。
- 这也就牵扯到在实际工作中,如何将面向对象和函数式编程两种不同的编程范式组合运用的问题。我们可以用面向对象编程的方式对系统的结构进行搭建,然后,用函数式编程的理念对函数接口进行设计。你可以把它理解成盖楼,用面向对象编程搭建大楼的骨架,用函数式编程设计门窗。
- 通过这两讲的例子,相信你已经感受到,一个好的函数式的接口,需要我们做的同样是“分离关注点”。虽然你不知道组合的方式会有多少种,但你知道,所有的变化其实就是一些基础元素的不断组合。在后面的巩固篇中,讲到 Moco 时,我们还会领略到这种函数式接口的魅力。
- 
- 19 | 函数式编程之不变性:怎样保证我的代码不会被别人破坏?
- 经过前两讲的介绍,你已经认识到了函数式编程的能力,函数以及函数之间的组合很好地体现出了函数式编程的巧妙之处。不过,我们在讲编程范式时说过,学习编程范式不仅要看它提供了什么,还要看它约束了什么。这一讲,我们就来看看函数式编程对我们施加的约束。
- 在软件开发中,有一类 Bug 是很让人头疼的,就是你的代码怎么看都没问题,可是运行起来就是出问题了。我曾经就遇到过这样的麻烦,有一次我用 C 写了一个程序,怎么运行都不对。我翻来覆去地看自己的代码,看了很多遍都没发现问题,不得已,只能一步一步跟踪代码。最后,我发现我的代码调用到一个程序库时,出现了与预期不符的结果。
- 这个程序库是其他人封装的,我只是拿过来用。按理说,我调用的这个函数逻辑也不是特别复杂,不应该出现什么问题。不过,为了更快定位问题,我还是打开了这个程序库的源代码。经过一番挖掘,我发现在这个函数底层实现中,出现了一个全局变量。
- 分析之后,我发现正是这个全局变量引起了这场麻烦,因为在我的代码执行过程中,有别的程序会调用另外的函数,修改这个全局变量的值,最终,导致了我的程序执行失败。从表面上看,我调用的这个函数和另外那个函数八竿子都打不到,但是,它们却通过一个底层的全局变量,产生了相互的影响。
- 这就是一类非常让人头疼的 Bug。有人认为这是全局变量使用不当造成的,在 Java 设计中,甚至取消了全局变量,但类似的问题并没有因此减少,只是以不同面貌展现出来而已,比如,static 变量。
- 那么造成这类问题的真正原因是什么呢?==真正原因就在于变量是可变的==。
## 变之殇
- 你可能会好奇,难道变量不就应该是变的吗?为了更好地理解这一类问题,我们来看一段代码:
class Sample1 {
private static final DateFormat format =
new SimpleDateFormat("yyyy.MM.dd");
public String getCurrentDateText() {
return format.format(new Date());
}
- 如果你不熟悉 JDK 的 SimpleDateFormat,你可能会觉得这段代码看上去还不错。然而,这段代码在多线程环境下就会出问题。正确的用法应该是这样:
public class Sample2 {
public String getCurrentDateText() {
DateFormat format = new SimpleDateFormat("yyyy.MM.dd");
return format.format(new Date());
}
- 两段代码最大的区别就在于,SimpleDateFormat 在哪里构建。一个是被当作了一个字段,另一个则是在函数内部构建出来。这两种不同做法的根本差别就在于,SimpleDateFormat 对象是否共享。
- 为什么这个对象共享会有问题呢?翻看 format 方法的源码,你会发现这样一句:
- 这里的 calendar 是 SimpleDateFormat 这个类的一个字段,正是因为在 format 的过程中修改了 calendar 字段,所以,它才会出问题。
- 我们来看看这种问题是怎么出现的,就像下面这张图看到的:
- 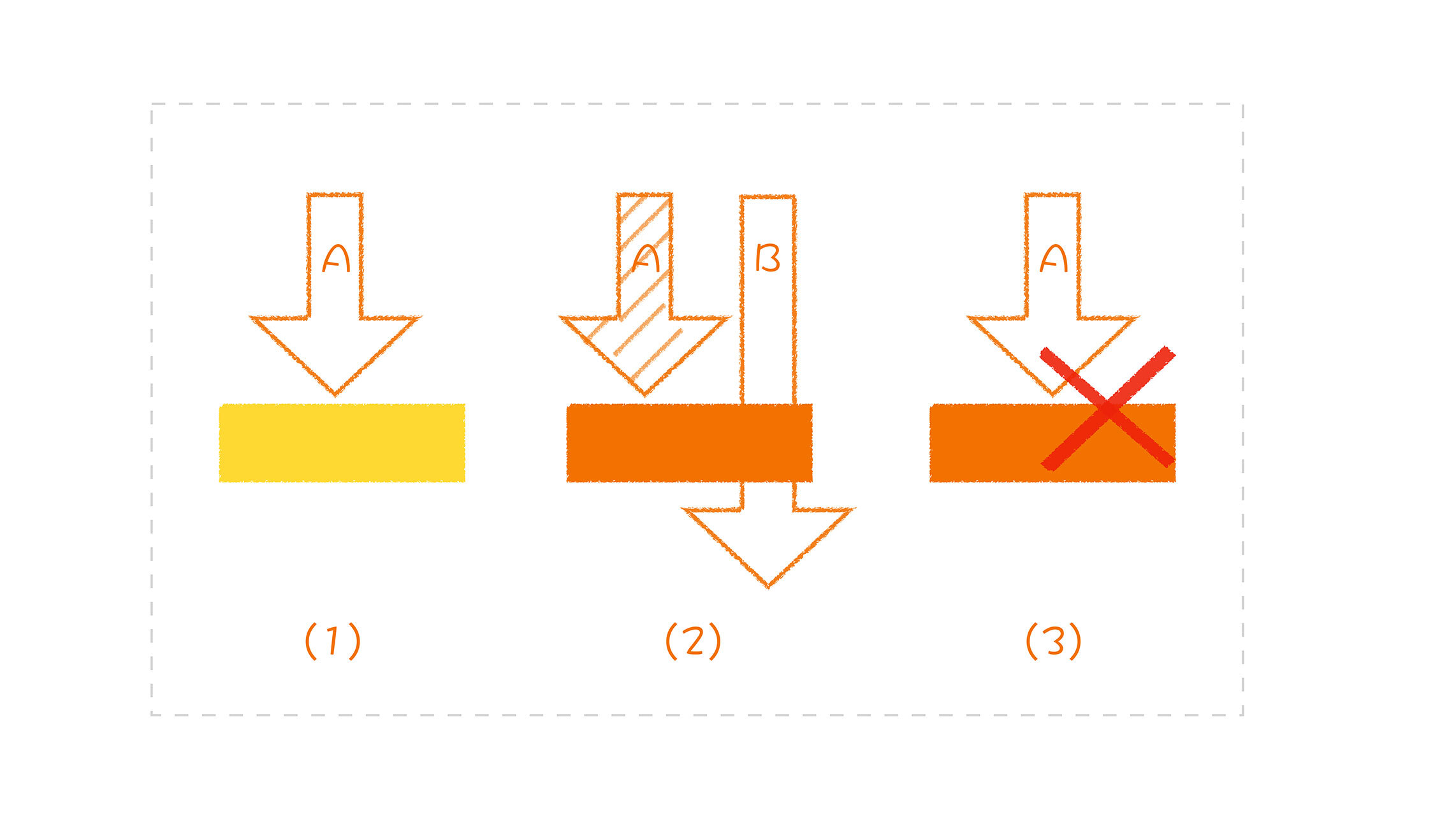
- A 线程把变量的值修改成自己需要的值;
- 这时发生线程切换,B 线程开始执行,将变量的值修改成它所需要的值;
- 线程切换回来,A 线程继续执行,但此时变量已经不是自己设置的值了,所以,执行会出错。
- 回到 SimpleDateFormat 上,问题是一样的,calendar 就是那个共享的变量。一个线程刚刚设置的值,可能会被另外一个线程修改掉,因此会造成结果的不正确。而在 Sample2 的写法中,通过每次创建一个新的 SimpleDateFormat 对象,我们将二者之间的共享解开,规避了这个问题。
- 那如果我还是想按照 Sample1 的写法写,SimpleDateFormat 这个库应该怎么改写呢?可能你会想,SimpleDateFormat 的作者没写好,如果换我写,我就会给它加上一个同步(synchronized)或者加上锁(Lock)。你甚至都没有注意,你轻易地将多线程的复杂性引入了进来。还记得我在分离关注点那节讨论的问题吗,多线程是另外一个关注点,能少用,尽量少用。
- 一个更好的办法是将 calendar 变成局部变量,这样一来,不同线程之间共享变量的问题就得到了根本的解决。但是,这类非常头疼的问题在函数式编程中却几乎不存在,这就依赖于函数式编程的不变性。
## 不变性
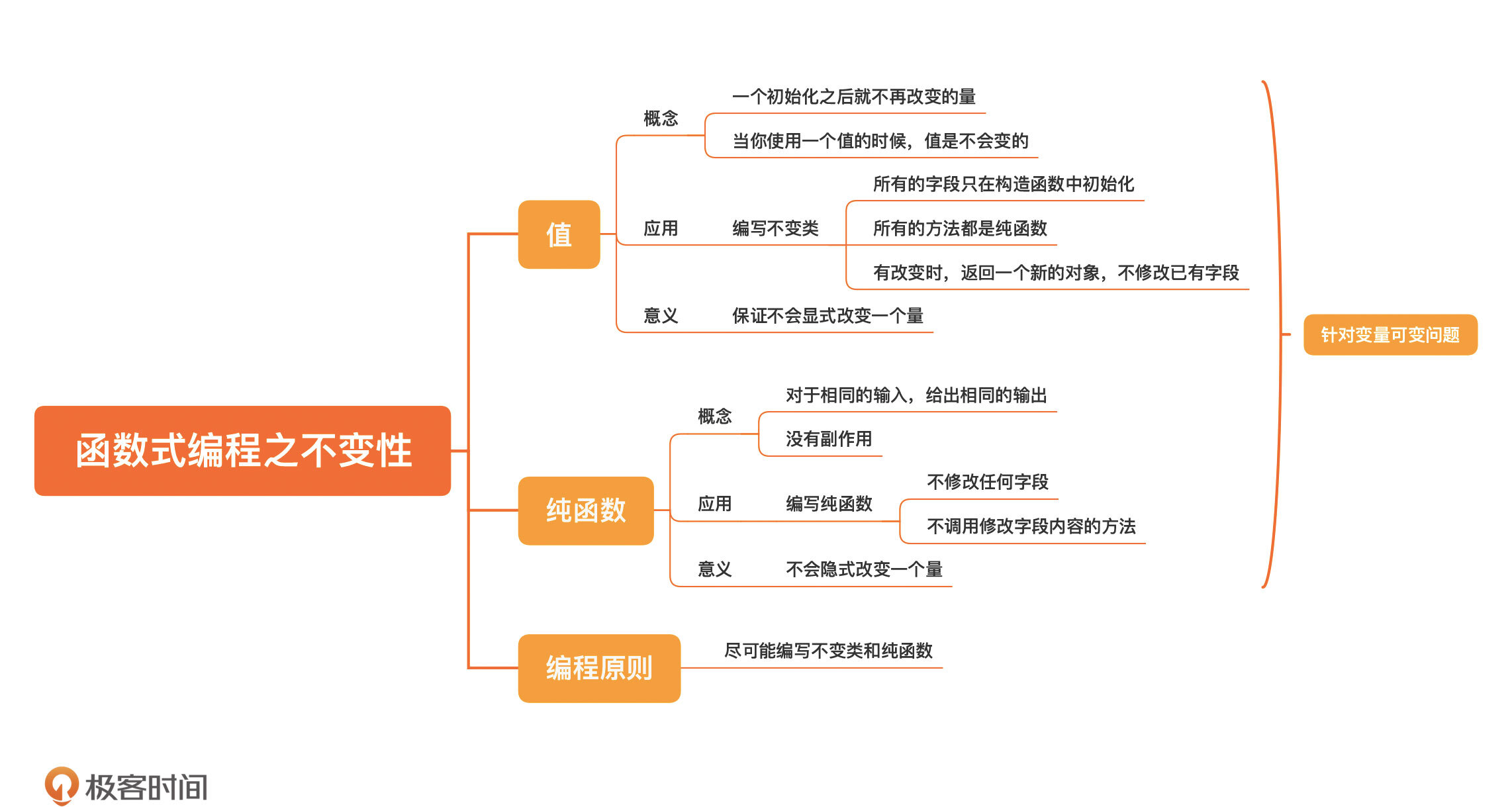
- 函数式编程的不变性主要体现在==值和纯函数上==。
- 值,你可以将它理解为一个初始化之后就不再改变的量,换句话说,当你使用一个值的时候,值是不会变的。
- 纯函数,是符合下面两点的函数:
- 对于相同的输入,给出相同的输出;
- 没有副作用。
- 把值和纯函数合起来看,值保证不会显式改变一个量,而纯函数保证的是,不会隐式改变一个量。
- 我们说过,函数式编程中的函数源自数学中的函数。在这个语境里,函数就是纯函数,一个函数计算之后是不会产生额外的改变的,而函数中用到的一个一个量就是值,它们是不会随着计算改变的。所以,在函数式编程中,计算天然就是不变的。
- 正是由于不变性的存在,我们在前面遇到的那些问题也就不再是问题了。一方面,如果你拿到一个量,这次的值是 1,下一次它还是 1,我们完全不用担心它会改变。另一方面,我们调用一个函数,传进去同样的参数,它保证给出同样的结果,行为是完全可以预期的,不会碰触到其他部分。即便是在多线程的情况下,我们也不必考虑同步的问题,后续一系列的问题也就不存在了。
- 这与我们习惯的方式有着非常大的区别,因为传统方式的基础是面向内存单元的,改来改去甚至已经成为了程序员的本能。所以,我们对 counter = counter + 1 这种代码习以为常,而初学编程的人总会觉得这在数学上是不成立的。
- 在之前的讨论中,我们说过,传统的编程方式占优的地方是执行效率,而现如今,这个优点则越来越不明显,反而是因为到处可变而带来了更多的问题。相较之下,我们更应该在现在的设计中,考虑借鉴函数式编程的思路,把不变性更多地应用在我们的代码之中。
- 那怎么应用呢?首先是值。我们可以编写不变类,就是对象一旦构造出来就不能改变,Java 程序员最熟悉的不变类应该就是 String 类,怎样编写不变类呢?
- 所有的字段只在构造函数中初始化;
- 所有的方法都是纯函数;
- ==如果需要有改变,返回一个新的对象,而不是修改已有字段。==
- 前面两点可能还好理解,最后一点,我们可以看一下 Java String 类的 replace 方法签名:
- `String replace(char oldChar, char newChar);`
- 在这里,我们会用一个新的字符(newChar)替换掉这个字符串中原有的字符(oldChar),但我们并不是直接修改已有的这个字符串,而是创建一个新的字符串对象返回。这样一来,使用原来这个字符串的类并不用担心自己引用的内容会随之变化。
- 有了这个基础,等我们后面学习领域驱动设计的时候,你就很容易理解值对象(Value Object)是怎么回事了。
- 我们再来看纯函数。==编写纯函数的重点是,不修改任何字段,也不调用修改字段内容的方法。因为在实际的工作中,我们使用的大多数都是传统的程序设计语言,而不是严格的函数式编程语言,不是所有用到的量都是值。所以,站在实用性的角度,如果要使用变量,就使用局部变量==。
- 还有一个实用性的编程建议,就是使用语法中不变的修饰符,比如,Java 就尽可能多使用 final,C/C++ 就多写 const。无论是修饰变量还是方法,它们的主要作用就是让编译器提醒你,要多从不变的角度思考问题。
- 当你有了用不变性思考问题的角度,你会发现之前的很多编程习惯是极其糟糕的,比如,Java 程序员最喜欢写的 setter,它就是提供了一个接口,修改一个对象内部的值。
- 不过,==纯粹的函数式编程是很困难的,我们只能把编程原则设定为尽可能编写不变类和纯函数==。但仅仅是这么来看,你也会发现,自己从前写的很多代码,尤其是大量负责业务逻辑处理的代码,完全可以写成不变的。
- 绝大多数涉及到可变或者副作用的代码,应该都是与外部系统打交道的。能够把大多数代码写成不变的,这已经是一个巨大的进步,也会减少许多后期维护的成本。
- 而正是不变性的优势,有些新的程序设计语言默认选项不再是变量,而是值。比如,在 Rust 里,你这么声明的是一个值,因为一旦初始化了,你将无法修改它:
- placeholder
- 而如果你想声明一个变量,必须显式地告诉编译器:
- placeholder
- Java 也在尝试将值类型引入语言,有一个专门的Valhalla 项目就是做这个的。你也看到了,不变性,是减少程序问题的一个重要努力方向。
- 现在回过头来看编程范式那一讲里说的约束:
- 函数式编程,限制使用赋值语句,它是对程序中的赋值施加了约束。
- 理解了不变性,你应该知道这句话的含义了,一旦初始化好一个量,就不要随便给它赋值了。
- 
## 设计原则与模式
## 单一职责原则
## 开放封闭原则
## Liskov替换原则
## 接口隔离原则
## 依赖倒置原则
## 设计模式
## 简单设计
## 设计方法
## 从零开始设计一个软件
## 划分系统的模块
## 像写故事一样找出模型